Переупорядочивание данных
Ряд инструкций позволяют переупорядочивать данные внутри регистра XMM/YMM.
(v)pshufb
Инструкция pshufb позволяет перемешать данные в соответствии с индексами:
pshufb xmmdest, xmmsrc/mem128
Первый операнд представляет регистр XMM, байтовые дорожки которого будут переупорядочиваться. Второй операнд (либо регистр XMM, либо 128-битная переменная) представляет собой массив из 16 байтов, которые содержат индексы для перемешивания элементов. Если второй операнд является переменной, он должен быть выровнен по 16-байтовой границе.
Каждый байт из второго операнда имеет следующую композицию:

Первые 4 бита хранят индекс байта регистра XMM, из которого надо взять данные. 4 бита позволяют закодировать 16 чисел, что достаточно для 16 дорожек. Биты с 4 по 6 игнорируются. Бит 7 управляет перемешиванием: если этот бит содержит 1, то биты индекса дорожки также игнорируются, а в соответствующем байте в регистре XMM сохраняется 0. Если этот бит содержит 0, то инструкция pshufb выполняет операцию перемешивания.
Инструкция pshufb выполняется для каждой дорожки. Инструкция сначала создает временную копию регистра XMM. Затем для каждого байта индекса (страший бит которых равен 0) инструкция копирует дорожку, указанную в младших 4 битах. Например:
.data
nums byte 11, 12, 13, 14, 15, 16, 17, 18
byte 19, 20, 21, 22, 23, 24, 25, 26
indexes byte 0, 1, 4, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15
.code
main proc
movdqa xmm0, oword ptr nums
pshufb xmm0, oword ptr indexes
ret
main endp
end
Здесь в XMM0 вначале загружается массив из 16 однобайтовых чисел nums. Поскольку инструкция копирования данных movdqa принимает 16-байтное число, то вектор nums приводим
к типу oword. С помощью инструкции pshufb перемешиваем данные в XMM0, используя индексы indexes:
indexes byte 0, 1, 3, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15
Индексация начинаяется с 0, то есть индекс 0 представляет первый элемент в векторе. Например, по индексу 0 в массиве indexes располагается число 0. Это означает, что для этой дорожки данные будут браться из дорожки с индексом 0, то есть по сути из той же самой дорожки. В итоге те данные, которые были в этой дорожке, они и останутся после выполнения инструкции. И так почти для всех дорожек, кроме дорожки с индексом 2. Она хранит число 4. То есть для дорожки с индексом 2 данные будут браться из дорожки с индексом 4.
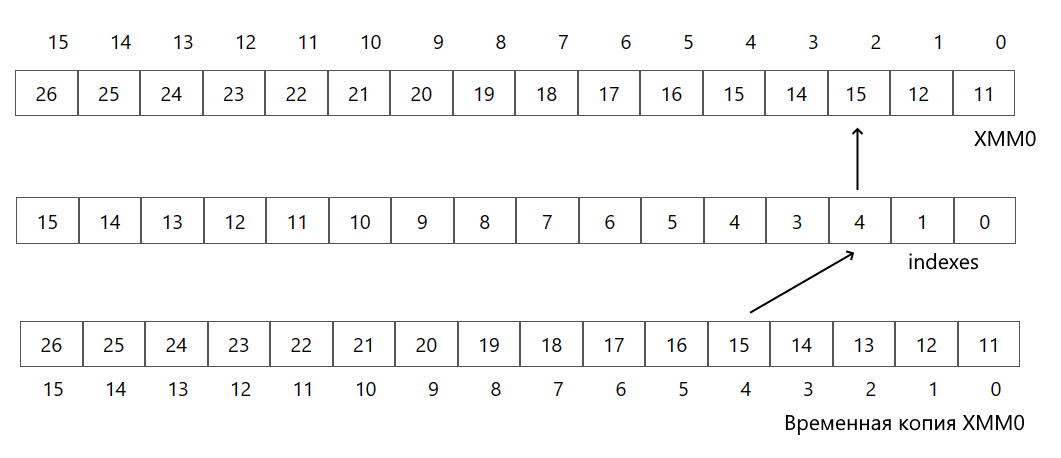
То есть в итоге в дорожке 2 регистра XMM после выполненния программы будет число 15 (из дорожки 4).
Чтобы перевернуть данные мы могли бы использовать индексы в обратном порядке:
.data
nums byte 11, 12, 13, 14, 15, 16, 17, 18
byte 19, 20, 21, 22, 23, 24, 25, 26
; для переворота вектора nums
reversed byte 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0
.code
main proc
movdqa xmm0, oword ptr nums
pshufb xmm0, oword ptr reversed
ret
main endp
end
Инструкция vpshufb в качестве второго операнда принимает регистр, из которого берутся данные, и использует этот регистр вместо создания копии регистра из первого операнда. Массив индексов передается через третий параметр. Также данная инструкция позволяет указать 256-битные регистры YMM в дополнение к 128-битным регистрам XMM
vpshufb xmmdest, xmmsrc, xmmindex/mem128 vpshufb ymmdest, ymmsrc, ymmindex/mem256
(v)pshufd
Инструкции pshufd и vpshufd переупорядочивают 32-битные целые числа (dword) в регистрах XMM и YMM
аналогично инструкциям (v)pshufb:
pshufd xmmdest, xmmsrc/mem128, imm8 vpshufd xmmdest, xmmsrc/mem128, imm8 vpshufd ymmdest, ymmsrc/mem256, imm8
Первый операнд представляет целевой регистр, в котором будут храниться перемешанные значения. Второй операнд является источником, из которого инструкция выбирает двойные слова для размещения в целевой регистре (если второй операнд - переменная, то она должна быть выровнена по 16- или 32-байтовой границе). Третий операнд представляет собой 8-разрядное непосредственное значение, которое хранит индексы двойных слов для выбора из второго операнда.
Третий операнд имеет определенную организацию битов. Определенные биты определяют индекс данных из операнда-источника, которые помещаются в определенную дорожку целевого регистра
Биты | Дорожка |
0-1 | 0 |
2-3 | 1 |
4-5 | 2 |
6-7 | 3 |
Поскольку в данном случае копируются двойные слова (32 бита), то под дорожкой понимаются 32 бита целевого регистра. Так, биты 0-1 определяют двойное слово из операнда-источника, которое помещается в первые 32 бита целевого регистра. Биты 2-3 определяют двойное слово из операнда-источника, которое помещается во вторые 32 бита целевого регистра. Биты 4-5 определяют двойное слово из операнда-источника, которое помещается во третьи 32 бита целевого регистра. Наконец, биты 6 -7 определяют значение, которое помещается во четвертые 32 бита целевого регистра.
Разница между 128-битными инструкциями pshufd и vpshufd заключается в том, что pshufd оставляет старшие 128 бит регистра YMM без изменений, а
vpshufd обнуляет их.
256-битная версия vpshufd (при использовании регистров YMM в качестве исходного и целевого операндов) также использует 8-битный непосредственный операнд
в качестве значения индекса. Каждое 2-битное значение индекса манипулирует двумя значениями dword в регистрах YMM.
Биты 0-1 управляют двойными словами 0 и 4, биты 2-3 управляют двойными словами 1 и 5, биты 4-5 управляют двойными словами 2 и 6, а биты 6-7 управляют двойными словами 3 и 7.
Пример применения:
.data
nums0 dword 11, 12, 13, 14
nums1 dword 21, 22, 23, 24
.code
main proc
movaps xmm0, nums0
pshufd xmm0, nums1, 000001111b
ret
main endp
end
Здесь изначально в регистр XMM0 загружается вектор nums0. С помощью инструкции pshufd заменяем некоторые его элементы числами из вектора nums1.
Индексы определяются непосредственным операндом 000001111b, который задан в бинарной форме. Где мы видим, что для дорожки с индексом 0 и 1 регистра XMM0 будет браться
число dword по индексу 3 из nums1, для дорожки 2 и 3 - число по индексу 0.
(v)pshuflw и (v)pshufhw
Инструкции (v)pshuflw и (v)pshufhw обеспечивают перемешивание 16-разрядных чисел в регистре XMM или YMM:
pshuflw xmmdest, xmmsrc/mem128, imm8 pshufhw xmmdest, xmmsrc/mem128, imm8 vpshuflw xmmdest, xmmsrc/mem128, imm8 vpshufhw xmmdest, xmmsrc/mem128, imm8 vpshuflw ymmdest, ymmsrc/mem256, imm8 vpshufhw ymmdest, ymmsrc/mem256, imm8
128-битные варианты (v)pshuflw копируют старшие 64 бита операнда-источника в те же позиции в целевом регистре.
Затем с помощью третьего операнда индекса - imm8 они выбирают 16-битные дорожки от 0 до 3 в младших 64 битах операнде-источнике, значения которых копируются
в младшие 16-битные дорожки целевого регистра. Например, если младшие 2 бита операнда imm8 равны 10b, то инструкция pshuflw
копирует дорожку 2 из источника в дорожку 0 целевого регистра. При этом pshuflw не изменяет старшие 128 бит перекрывающего регистра YMM, тогда как vpshuflw
обнуляет эти биты.
256-битная инструкция vpshuflw (с целевым регистром YMM) также копирует 16-битное число из дорожки в источнике, на которую указывает индексу в imm8. Но это число копируется
одновременно в определенную дорожку в старших 128 битах и в младших 128 битах целевого регистра YMM.
128-битные варианты (v)pshufhw копируют младшие 64 бита операнда-источника в те же позиции в целевом регистре.
Затем с помощью операнда индекса imm8 они выбирают 16-битные дорожки от 4 до 7 в старших 64 битах операнда-источника, значения которых копируются
в старшие 16-битные дорожки целевого регистра.
256-битная инструкция vpshufhw также копирует 16-битное число из дорожки в источнике, на которую указывает индексу в imm8. Но это число копируется
одновременно в определенную дорожку в старших 128 битах и в младших 128 битах целевого регистра YMM.
shufps и shufpd
Инструкции shufps и shufpd копируют соответственно 32- и 64-разрядные числа с плавающей точкой из операнда-источника и помещают их в указанные позиции в целевом регистре. Третий операнд определяет индексы дорожек операнда-источника, которые копируются в соответствующие дорожки целевого регистра.
shufps xmmdest, xmmsrc2/mem128, imm8 shufpd xmmdest, xmmsrc2/mem128, imm8
Третий операнд (imm8) представляет массив из четырех 2-битных чисел. Его биты 0 и 1 выбирают 32-битное число с плавающей точкой из одной из четырех дорожек первого операнда для сохранения в дорожку 0 целевого регистра, которым также является первый операнд.
Аналогично биты 2 и 3 выбирают 32-битное число из одной из четырех дорожек первого операнда для сохранения в дорожку 1 первого операнда.
Биты 4 и 5 выбирают 32-битное число из одной из четырех дорожек второго операнда для сохранения в дорожке 2 первого операнда.
Биты 6 и 7 выбирают 32-битное число из одной из четырех дорожек второго операнда для сохранения в дорожку 3 первого операнда.
Рассмотрим небольшой пример:
.data
nums0 dword 11, 12, 13, 14
nums1 dword 21, 22, 23, 24
.code
main proc
movaps xmm0, nums0
movaps xmm1, nums1
shufps xmm0, xmm1, 11100100b
ret
main endp
end
В XMM0 и XMM1 загружаются соответственно векторы nums0 и nums1. Инструкция shufps для перемешивания данных применяет индексный операнд 11100100b.
Таким образом, сопоставление значений будет выглядеть следующим образом:
Биты
00: в XMM0[0-31] копируются данные из XMM0[0-31] (по сути остаются начальные данные)Биты
01: в XMM0[32-63] копируются данные из XMM0[32-63]Биты
10: в XMM0[64-95] копируются данные из XMM1[64-95]Биты
11: в XMM0[96-127] копируются данные из XMM0[96-127]
Таким образом, в итоге в регистре XMM0 окажется вектор 11, 12, 23, 24
Инструкция shufpd работает аналогично, только перемешивает 64-битные числа. Соответственно индексы в третьем операнде указывают на индексы 64-битных дорожек. Поскольку в регистре XMM могут храниться только два 64-разрядных значения, для выбора дорожки требуется только один бит - 0 или 1. Поэтому биты со 2 по 7 в операнде imm8 игнорируются. Бит 0 операнда imm8 выбирает одну из двух 64-битных дорожек первого операнда для компирования в дорожку 0 целевого регистра (он же первый операнд). Бит 1 операнда imm8 выбирает одну из двух 64-битных дорожек второго операнда для компирования в дорожку 1 целевого регистра. Например:
.data
nums0 qword 11, 12
nums1 qword 21, 22
.code
main proc
movapd xmm0, nums0
movapd xmm1, nums1
shufpd xmm0, xmm1, 01b
ret
main endp
end
Здесь после выполнения программы в регистре XMM0 будет храниться вектор 12, 21
vshufps и vshufpd
Инструкции vshufps и vshufpd аналогичны инструкциям shufps и shufpd. Они позволяют перемешивать значения в 128-битных регистрах XMM
или 256-битных регистрах YMM. Инструкции vshufps и vshufpd имеют четыре операнда:
vshufps xmmdest, xmmsrc1, xmmsrc2/mem128, imm8 vshufpd xmmdest, xmmsrc1, xmmsrc2/mem128, imm8 vshufps ymmdest, ymmsrc1, ymmsrc2/mem256, imm8 vshufpd ymmdest, ymmsrc1, ymmsrc2/mem256, imm8
первый операнд - целевой регистр XMM или YMM, в который копируются данные. Второй и третий операнды - два источника (второй операнд должен быть регистром XMM или YMM, а третий операнд может быть регистром XMM или YMM или 128- или 256-битной переменной). Четверный операнд - индексный операнд imm8.
128-битные версии инструкций vshufps и vshufpd аналогичны инструкциям shufps и shufpd за тем исключением, что для младших 64 бит целевого регистра данные копируются из второго операнда, а для старших 64 бит - из третьего операнда.
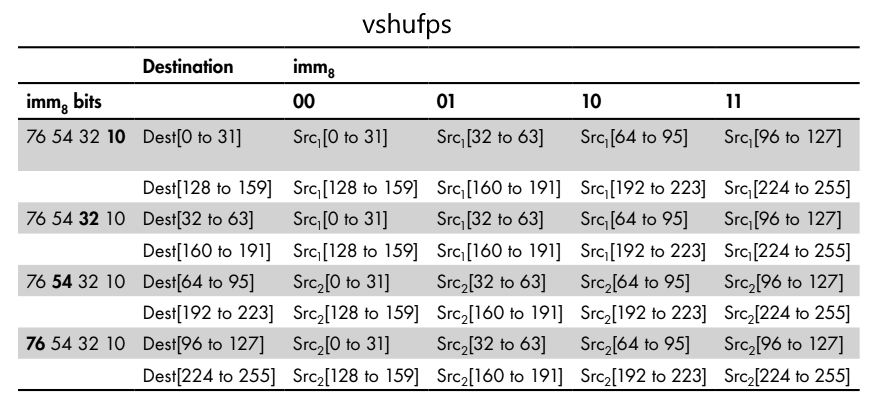
Для 256-битной инструкции vshufps биты 0-1 и 2-3 операнда imm8 определяют индексы дорожек второго операнда, из которых берутся данные для 32-битных дорожек 0 и 1 целевого регистра XMM.
А биты 4-5 и 6-7 операнда imm8 определяют индексы дорожек третьего операнда, из которых берутся данные для дорожек 2 и 3 целевого регистра XMM. Для второй 128-битной половины целевого регистра YMM процесс повторяется.
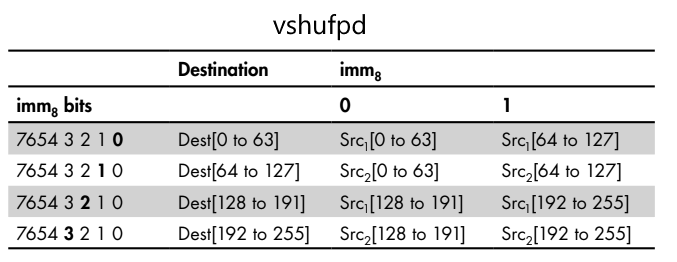
Для 256-битной инструкции vshufpd бит 0 операнда imm8 определяет индекс дорожки второго операнда, из которой берется значение для 64-битной дорожки 0 целевого регистра XMM.
А бит 1 операнда imm8 определяет индекс дорожки третьего операнда, из которой берется значение для 64-битной дорожки 1 целевого регистра XMM.. Для второй 128-битной половины целевого регистра YMM процесс повторяется.
- Глава 1. Введение в ассемблер Intel x86-64
- Глава 2. Основы ассемблера MASM для Intel x86-64
- Определение данных и их типы. Секция .data
- Инструкция mov. Копирование данных
- Сложение и вычитание. add и sub
- Переходы. Инструкция jmp
- Флаги состояния и условные переходы
- Сравнение. Инструкция CMP
- Инструкции условного копирования
- Логические операции
- Сдвиг и вращение
- Умножение. mul и imul
- Деление. Инструкции div и idiv
- Установка битов по условию. setc
- Манипуляции битами. BMI
- Константы
- Глава 3. Работа с данными и памятью
- Глава 4. Базовые конструкции
- Глава 5. Арифметика больших чисел
- Глава 6. Процедуры
- Глава 7. Организация программы
- Глава 8. FPU, SSE числа с плавающей точкой
- Регистры FPU
- Числа с плавающей точкой
- Загрузка данных и преобразование чисел в FPU
- Сложение чисел с плавающей точкой в FPU
- Вычитание чисел с плавающей точкой в FPU
- Умножение чисел с плавающей точкой в FPU
- Деление чисел с плавающей точкой в FPU
- Дополнительные математические инструкции FPU
- Сравнение чисел с плавающей точкой в FPU
- Расширения SSE для чисел с плавающей точкой
- Арифметика чисел с плавающей точкой в SSE
- Сравнение чисел с плавающей точкой в SSE
- Десятичная арифметика и двоично-десятичный формат BCD
- Глава 9. SIMD
- Расширения SSE и AVX/AVX2
- Копирование данных с помощью инструкций SIMD
- Копирование чисел с плавающей точкой
- Переупорядочивание данных
- Логические операции SSE/AVX
- Операции сдвига SSE/AVX
- Сложение с помощью инструкций SSE/AVX
- Вычитание с помощью инструкций SSE/AVX
- Умножение с помощью инструкций SSE/AVX
- Математические инструкции SSE/AVX
- Сравнение целых чисел в SSE/AVX
- Преобразования целых чисел в SSE/AVX
- Арифметические операции с плавающей точкой в SSE/AVX
- Сравнение чисел с плавающей точкой в SIMD
- Преобразование чисел с плавающей точкой в целые числа и обратно
- Загрузка в регистры константных значений
- Сохранение состояния регистров SSE/AVX
- Глава 10. Строки
- Глава 11. Макросы
- Глава 12. Взаимодействие с кодом на C/C++
- Глава 13. Взаимодействие с WinAPI
- Глава 14. Исследование и дизассемблирование файлов