Стек
Стек — это динамическая структура данных, которая хранит важную информация о программе, включая локальные переменные, информацию о подпрограммах и временные данные. В архитектуре x86-64 стек реализуется с помощью сегмента стека. Процессор x86-64 управляет стеком через регистр RSP (указатель стека). Когда программа начинает выполняться, операционная система инициализирует регистр RSP адресом последней ячейки памяти в сегменте стека. В процессе работы программы данные записываются в сегмент стека или, наоборот, извлекаются из стека.
Стек растет от больших адресов к меньшим, то есть при добавлении в стек данных, адрес добавляемых данных будет уменьшаться.
При запуске программы обычно стек выровнен по 8-байтовой границе. Например, RSP может хранить адрес 0x0000009BA9EFF9A8 (адрес оканчивается на 8).
Для добавления данных в стек применяется инструкция push, которая имеет следующий синтаксис:
push reg16 push reg64 push mem16 push mem64 pushw constant16 push constant32 ; расширяется до 64 бит
Итак, мы можем добавить в стек значения 16- и 64-разрядного регистра, 16- и 64-разрядной переменной и 16- и 32-разрядной константы (32-битная констранта расширяется до 64 бит).
При выполнении инструкции push от значения регистра RSP вычитается размер операнда. А по адресу, который хранится в стеке, помещается значение операнда.
RSP = RSP - размер операнда [RSP] = значение операнда
Инструкция pop позволяет, наоборот, взять из стека значение, адрес которого хранится в текущий момент в регистре RSP. Эта инструкция имеет следующий синтаксис
pop reg16 pop reg64 pop memory16 pop memory64
Инструкция в качестве операнда получает место, куда надо сохранить данные из стека. Это может быть или 16- и 64-разрядный регистр, или 16- и 64-разрядная переменная. При выполнении этой инструкции в операнд помещается значение, которое хранится в адресе из RSP. А само значение RSP увеличивается на размер операнда:
operand = [RSP] RSP = RSP + размер операнда
Например, возьмем следующую программу:
.code
main proc
mov rdx, 15
push rdx ; в конец стека помещаем содержимое регистра RDX
pop rax ; значение из конца стека помещаем в регистр RAX
ret
main endp
end
Допустим, регистр RSP содержит изначально адрес 00FF_FFF8h.
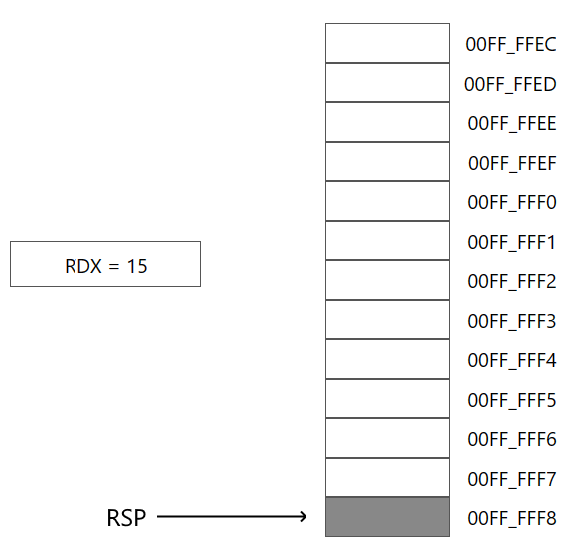
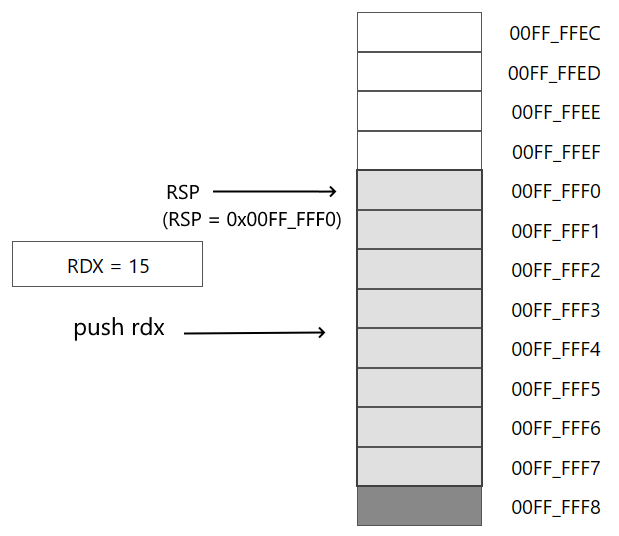
Пусть в регистре RDX хранится некоторое значение, которое с помощи инструкции push заталкивается в стек:
push rdx
В результате в последующие 8 байт начиная с адреса, который хранится в RSP, помещается значение из регистра RDX (в данном случае число 15). А в регистр RSP будет помещен адрес RSP-8, то есть условно 00FF_FFF0h и сохранит текущее значение регистра RDX в ячейках памяти начиная с 00FF_FFF0h по 00FF_FFF7h, то есть займет 8 байт.
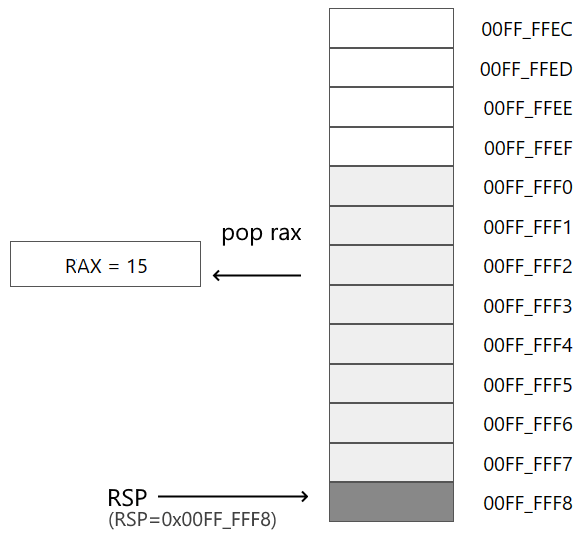
Затем извлекаем из стека значение по адресу, который хранится в RSP, в регистр RAX:
pop rax
В результате в RAX помещается число из стека (в данном случае число 15). А в регистр RSP будет помещен адрес RSP+8, то есть условно 00FF_FFF8h.
Принцип LIFO и сохранение регистров в стек
Наиболее распространенное использование команд push и pop — это сохранение значений регистров во время промежуточных вычислений. Поскольку регистры — лучшее место для хранения временных значений, и регистры также могут потребоваться для других операций, поэтому в процессе программы легко исчерпать регистры. Инструкции push и pop позволяют сохранить начальные значения регистров при старте программы, а при завершении программы восстановить эти значения.
Следует учитывать, что стек представляет структуру LIFO (Last In, First Out или Последний вошел, первый вышел), что значит, что получение данных из стека происходит в порядке, обратном их добавлению. Рассмотрим следующую программу:
.code
main proc
mov rax, 11
mov rdx, 33
push rax
push rdx
pop rax
pop rdx
ret
main endp
end
Допустим, в самом начале программы до добавления данных стек регистр RSP хранит адрес 00FF_FFF8.
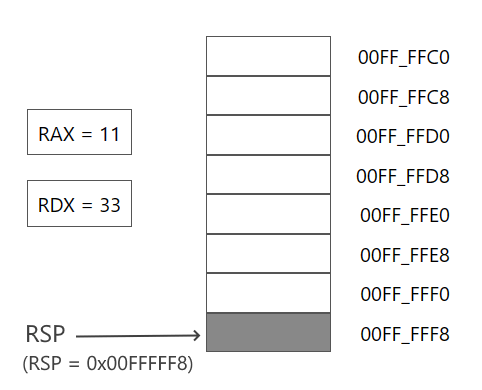
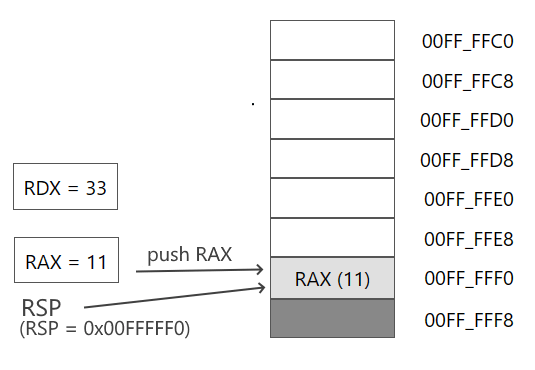
Затем добавляем в стек значение регистра RAX:
push rax
Адрес в RSP смещается на 8 байтов и указывает на адрес значения из регистра RAX
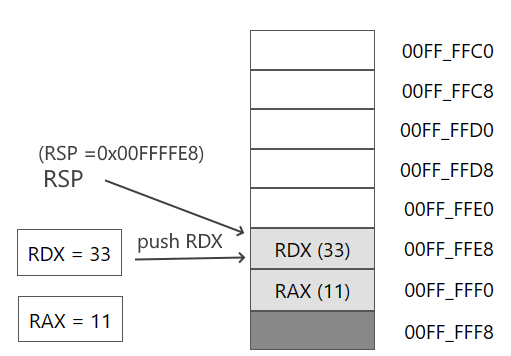
Далее добавляем в стек значение регистра RDX:
push rdx
Адрес в RSP смещается на 8 байтов и указывает на адрес значения из регистра RDX
После добавления мы последовательно извлекаем данные. Первая инструкция извлекает данные, на которые указывает регистр RSP, в регистр RAX:
pop rax
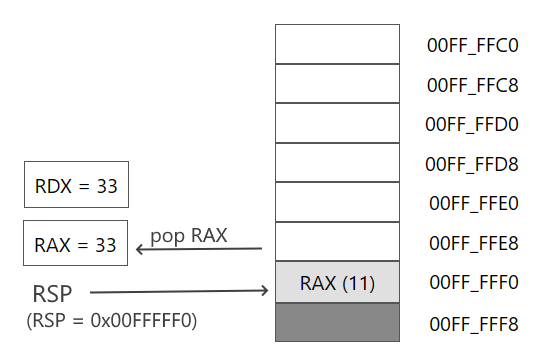
Однако поскольку RSP перед операцией извлечения указывал на адрес последнего добавленного значения - значения регистра RDX, то регистр RAX получит значение регистра RDX. Соответственно при последующей инструкции pop:
pop rdx
Регистр RDX получить значение регистра RAX, которое было в регистре RAX до добавления в стек.
Поэтому если мы хотим восстановить начальные значения регистров, то нам надо извлекать значения в порядке, обратном добавлению
push rax push rdx pop rdx ; Последним добавлено значение RDX, поэтому сначала извлекаем в RDX pop rax
В любом случае стоит помнить, что количество инструкций push и pop должно быть равно, сколько раз мы добавили данные в стек, столько раз мы должны получить данные из стека.
Сохранение флагов состояния
Ассемблер предоставляет дополнительную пару инструкций pushfq и popfq для сохранения и восстановления соответственно регистра RFLAGS (и всех флагов состояния). Например:
.code
main proc
pushfq ; сохраняем значения флагов
mov al, 255
add al, 2 ; 255 + 2 = 257 - флаг CF будет установлен
popfq ; восстанавливаем значения флагов
jc set ; если флаг CF установлен, переход к метке set
mov rax, 0
ret
set:
mov rax, 1
ret
main endp
end
Здесь инструкцией pushfq сначала сохраняем флаги. По умолчанию флаг переноса CF будет равен 0.
Затем выполняем сложение 255 + 2, что даст 257 и что очевидно за пределы разрядности регистра AL, соответственно будет установлен флаг переноса CF. Далее с помощью инструкции
jc set переходим к метке set, если флаг CF установлен. Однако перед этой инструкцией мы восстанавливаем флаги - popfq. То есть флаг CF получит свое значение 0, и никакого перехода к метке set
не произойдет.
Восстановление стека без извлечения данных
При завершении программы следует восстановить адрес в RSP. Как выше было показано, для этого мы можем использовать инструкцию pop. Однако может сложиться ситуация, что данные не требуется извлекать из стека.
Например, в зависимости от некоторых условий данные могут понадобиться, а могут не понадобиться. Если данные не нужны, извлекать каждые 8 байт отдельно с помощью инструкции pop
не имеет смысла, особенно если надо извлечь много данных из стека. И в этом случае мы можем восстановить адрес в RSP, просто прибавив нужное значение - смещение относительно начального
адреса. Например:
.code
main proc
mov rax, 2
mov rdx, 3
push rax
push rdx
add rsp, 16 ; прибавляем к адресу в RSP 16 байт
ret
main endp
end
Здесь в стек помещаем значения двух регистров - RAX и RDX, то есть адрес в RSP уменьшится на 16 байт (совокупный размер двух регистров). И чтобы быстро восстановить стек, прибавляем к адресу в RSP 16 байт:
add rsp, 16
Подобным образом можно вычитать из адреса в RSP определенное число, тем самым резервируя в стеке некоторое пространство:
.code
main proc
sub rsp, 16 ; смещаем адрес в RSP на 16 байт
mov rax, 2
add rsp, 16 ; восстанавливаем адрес в RSP
ret
main endp
end
Вычитание определенного количество байтов из стека может потребоваться при взаимодействии с некоторыми внешними функциями, например, на языках C/С++ для резервирования места для параметров функций или для выравнивания стека. Так, до вызова функций в Windows в соответствии с Microsoft ABI стек должен быть выровнен по 16-байтовой границе. При использовании инструкции push для сохранения значения регистра перед вызовом внешней функции надо убедиться, адрес RSP кратен 16 байтам.
Косвенная адресация в стеке
Как и в случае с любым другим регистром, в отношении регистра стека RSP можно использовать косвенную адресацию и обращаться к данным в стеке без смещения указателя RSP. Например:
.code
main proc
sub rsp, 16 ; резервируем в стеке 16 байт
mov rdx, 11
mov [rsp], rdx ; помещаем в стек значение регистра RDX
mov rax, [rsp] ; в RAX помещаем значение по адресу из RSP - число 11
add rsp, 16 ; восстанавливаем указатель стека
ret
main endp
end
В данном случае в стек помещаем число из регистра RDX - число 11.
mov [rsp], rdx
Подобную форму размещения данных в стеке можно рассматривать как альтернативу инструкции push, если нам не надо изменять значение указателя стека RSP. То есть мы можем
сохранить таким образом данные по адресу в RSP, но после этого RSP продолжает хранить тот же адрес.
Далее в регистр RAX помещаем значение, которое располагается по адресу из RSP. Фактически это тот адрес, где располагается число 11.
mov rax, [rsp]
Аналогично можно применять смещения и масштабирование. Например:
.code
main proc
push 12
push 13
push 14
mov rax, [rsp + 8] ; [rsp + 8] - адрес значения 13
; извлекаем сохраненные значения в r8, r9, r10
pop r8
pop r9
pop r10
ret
main endp
end
Здесь в стек последовательно помещаются три числа 12, 13, 14. Каждое число будет занимать 8 байт. После добавления адрес в RSP будет указывать на адрес последнего добавленного числа - 14. И чтобы, например, получить предыдущее число - 13, нам надо к адресу в RSP прибавить 8. И в данном случае получаем это число в регистр RAX.
mov rax, [rsp + 8]
Соотвественно чтобы получить из стека первое число - 12, надо к адресу в RSP прибавить 16:
mov rax, [rsp + 16]
Другой пример:
.code
main proc
sub rsp, 16 ; резервируем в стеке 16 байт
mov rbx, 12
mov rdx, 13
mov [rsp], rbx ; помещаем значение из RBX по адресу RSP
mov [rsp+8], rdx ; помещаем значение из RDX по адресу RSP+8
mov rax, [rsp] ; в RAX помещаем значение по адресу из RSP
add rax, [rsp+8] ; складываем с числом из RSP+8
add rsp, 16 ; восстанавливаем данные из стека
ret
main endp
end
Здесь по адресу RSP располагается значение региста RBX, а по адресу RSP+8 - регистра RDX. В RAX извлекаем значение по адресу RSP (12), и затем складываем его со значением из RSP+8 (13). Таким образом, в RAX будет число 25.
Ограничения места в стеке
По умолчанию данные в стеке занимают то место, которое соответствует размеру регистра. Так, инструкция mov [rsp], rbx помещала в стек 8 байт из RBX. То есть данные в стеке
занимали 8 байт. Однако в примере выше в RBX хранится число, для которого достаточно и 1 байта, для него не требуется аж 8 байт. Пространство в стеке расходуется не экономично.
В этом случае с помощью преобразования данных мы можем явным образом указать, сколько байтов мы хотим использовать в стеке
.code
main proc
sub rsp, 16 ; резервируем в стеке 16 байт
mov rbx, 11
mov rdx, 12
mov [rsp], bl ; помещаем байт из BL по адресу RSP
mov [rsp+1], dl ; помещаем байт из DL по адресу RSP+1
movzx rax, byte ptr [rsp] ; в AL помещаем значение по адресу из RSP
add al, byte ptr [rsp+1] ; складываем с числом из RSP+1
add rsp, 16 ; восстанавливаем данные из стека
ret
main endp
end
Здесь в RAX извлекаем только один байт:
movzx rax, byte ptr [rsp]
Затем добавляем в AL еще один байт из стека, который хранится по адресу RSP+1:
add al, byte ptr [rsp+1]
Преобразования данных могут быть особенно актуальны, если необходимо поместить в стек непосредственный операнд:
.code
main proc
sub rsp, 16 ; резервируем в стеке 16 байт
mov qword ptr [rsp], 11 ; в стек помещаем число 11 - оно занимает 8 байт
mov word ptr [rsp+8], 15 ; по адресу в RSP+8 помещаем 2-байтное число 15
mov rax, qword ptr [rsp] ; RAX = 11
add ax, word ptr [rsp+8] ; складываем с числом из RSP+8
add rsp, 16 ; восстанавливаем данные из стека
ret
main endp
end
Здесь сначала помещаем в стек число 11, которое будет занисать 8 байт, так как мы приводим к типу qword:
mov qword ptr [rsp], 11
Затем по адресу RSP+2 помещаем число 15, которое будет занимать 2 байта:
mov word ptr [rsp+8], 15
Затем извлекаем эти данные и складываем их:
mov rax, qword ptr [rsp] ; RAX = 11 add ax, word ptr [rsp+8] ; складываем с числом из RSP+8
Стоит обратить внимание, что тип извлекаемых данных соответствует размеру регистра, либо при извлечение 1 байта применется операция расширения movzx/movsx.
Некорректное извлечение может привести к некорректным результатам:
.code
main proc
sub rsp, 16 ; резервируем в стеке 16 байт
mov byte ptr [rsp], 10 ; по адресу в RSP помещаем число 10
mov byte ptr [rsp+1], 11 ; по адресу в RSP+1 помещаем число 11
mov rax, [rsp] ; RAX = ?
add rsp, 16 ; восстанавливаем данные из стека
ret
main endp
end
Здесь в стек последовательно помещаем два байта - числа 10 и 11. Затем извлекам из стека данные. Но обратите внимание как идет извлечение
mov rax, [rsp] ; RAX = ?
Какое число окажется в регистре RAX? Здесь в регистр RAX из стека скопируются 8 байт, из которых первые два байта - это числа 10 и 11, остальные 6 байт неопределены. Соответственно результат в RAX неопределен. И чтобы взять только нужную нам порцию данных, следует использовать преобразование типов:
.code
main proc
sub rsp, 16 ; резервируем в стеке 16 байт
mov byte ptr [rsp], 10 ; по адресу в RSP помещаем число 10
mov byte ptr [rsp+1], 11 ; по адресу в RSP+1 помещаем число 11
movzx rax, byte ptr [rsp] ; RAX = 10
add rsp, 16 ; восстанавливаем данные из стека
ret
main endp
end
Расположение данных в стеке
Может возникнуть вопрос, как числа размером более одного байта сохраняются в стеке? Рассмотрим следующую программу:
.code main proc mov rdx, 0102030405060708h ; в RDX 8-байтное число push rdx ; сохраняем число из RDX в стек movzx rax, byte ptr [rsp] ; в RAX сохраняем 1 байт по адресу в RSP pop rdx ; извлекаем число из стека в RDX ret main endp end
Здесь в регистр RDX сохраняем 16-ричное число 0x0102030405060708. Далее это число помещаем в стек.
Затем с помощью инструкции movzx помещаем в RAX 1 байт, извлеченный из стека по адресу который хранится в RSP. Чему будет равен этот байт - 0, 1 или 8?
При добавлении в стек старшие биты числа располагаются по старшим адресам, а младшие биты по младшим адресам:
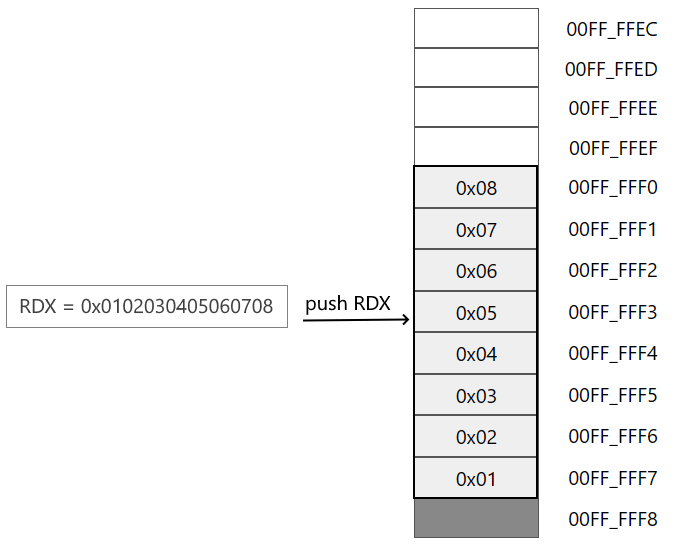
Соответственно в регистре RAX окажется число 0х08
Аналогично, если мы хотим получить старший байт 8-битного числа, то мы можем сместиться относительно адреса RSP вниз на 7 байт (то есть RSP+7):
movzx rax, byte ptr [rsp+7] ; RAX = 0x01
- Глава 1. Введение в ассемблер Intel x86-64
- Глава 2. Основы ассемблера MASM для Intel x86-64
- Определение данных и их типы. Секция .data
- Инструкция mov. Копирование данных
- Сложение и вычитание. add и sub
- Переходы. Инструкция jmp
- Флаги состояния и условные переходы
- Сравнение. Инструкция CMP
- Инструкции условного копирования
- Логические операции
- Сдвиг и вращение
- Умножение. mul и imul
- Деление. Инструкции div и idiv
- Установка битов по условию. setc
- Манипуляции битами. BMI
- Константы
- Глава 3. Работа с данными и памятью
- Глава 4. Базовые конструкции
- Глава 5. Арифметика больших чисел
- Глава 6. Процедуры
- Глава 7. Организация программы
- Глава 8. FPU, SSE числа с плавающей точкой
- Регистры FPU
- Числа с плавающей точкой
- Загрузка данных и преобразование чисел в FPU
- Сложение чисел с плавающей точкой в FPU
- Вычитание чисел с плавающей точкой в FPU
- Умножение чисел с плавающей точкой в FPU
- Деление чисел с плавающей точкой в FPU
- Дополнительные математические инструкции FPU
- Сравнение чисел с плавающей точкой в FPU
- Расширения SSE для чисел с плавающей точкой
- Арифметика чисел с плавающей точкой в SSE
- Сравнение чисел с плавающей точкой в SSE
- Десятичная арифметика и двоично-десятичный формат BCD
- Глава 9. SIMD
- Расширения SSE и AVX/AVX2
- Копирование данных с помощью инструкций SIMD
- Копирование чисел с плавающей точкой
- Переупорядочивание данных
- Логические операции SSE/AVX
- Операции сдвига SSE/AVX
- Сложение с помощью инструкций SSE/AVX
- Вычитание с помощью инструкций SSE/AVX
- Умножение с помощью инструкций SSE/AVX
- Математические инструкции SSE/AVX
- Сравнение целых чисел в SSE/AVX
- Преобразования целых чисел в SSE/AVX
- Арифметические операции с плавающей точкой в SSE/AVX
- Сравнение чисел с плавающей точкой в SIMD
- Преобразование чисел с плавающей точкой в целые числа и обратно
- Загрузка в регистры константных значений
- Сохранение состояния регистров SSE/AVX
- Глава 10. Строки
- Глава 11. Макросы
- Глава 12. Взаимодействие с кодом на C/C++
- Глава 13. Взаимодействие с WinAPI
- Глава 14. Исследование и дизассемблирование файлов