Умножение больших чисел
При умножении больших чисел нам надо умножить все части одного числа на все части другого числа и полученные результаты произведений сложить. Например, что такое произведение двух 32 разрядных чисел? Очевидно произведение 32 бит одного числа на 32 бита другого числа. Соответственно произведение двух 64-разрядных чисел - это произведение 64 бит одного числа на 64 бита другого числа. Однако мы можем представлить 64-разрядное число как число, у которого есть старшие 32 бита и младшие 32 бита. Тогда получится, что произведение двух 64-разрядных чисел равно
младшие 32 бита первого числа * младшие 32 бита второго числа + старшие 32 бита первого числа * младшие 32 бита второго числа + младшие 32 бита первого числа * старшие 32 бита второго числа + старшие 32 бита первого числа * старшие 32 бита второго числа
Что можно представить графически следующим образом:
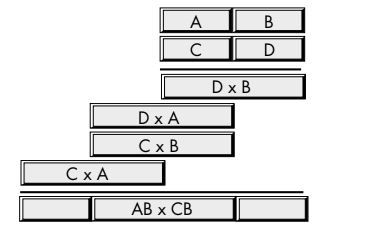
То есть вычисляем по отдельности произведения всех отдельных 32-разрядных частей двух чисел и складываем их. Рассмотрим пример:
.data
op1 qword 0ffffffffffffffffh
op2 qword 16
result oword ?
.code
main proc
; умножаем младшие 32 бита двух чисел
mov eax, dword ptr op1
mul dword ptr op2
mov dword ptr result, eax ; сохраняем младшие 32 бита результата
mov ecx, edx ; сохраняем старшие 32 бита результата
; умножаем младшие 32 бита op1 на старшие 32 бита op2
mov eax, dword ptr op1
mul dword ptr op2[4] ; получаем старшие 32 бита числа op2
add eax, ecx ; добавляем промежуточный результат умножения из ECX
adc edx, 0 ; сложение с битом переноса
mov ebx, eax ; сохраняем промежуточный результат
mov ecx, edx
; умножаем старшие 32 бита op1 на младшие 32 бита op2
mov eax, dword ptr op1[4] ; получаем старшие 32 бита числа op1
mul dword ptr op2 ; умножаем на младшие 32 бита op2
add eax, ebx ; добавляем промежуточный результат умножения из EBX
mov dword ptr result[4], eax ; сохраняем частичный результат
adc ecx, edx ; сложение с битом переноса
; умножаем старшие 32 бита двух чисел
mov eax, dword ptr op1[4]
mul dword ptr op2[4]
add eax, ecx ; добавляем промежуточный результат из ECX
adc edx, 0 ; сложение с битом переноса
mov dword ptr result[8], eax ; сохраняем младшую часть результата
mov dword ptr result[12], edx ; сохраняем старшую часть результата
mov eax, dword ptr result[8] ; eax = 15 или 0fh
ret
main endp
end
Здесь умножаем два числа типа qword (то есть 64-разрядные числа) - op1 и op2. Результат теоретически может быть 128-разрядным, и для его хранения определяем переменную result,
которая представляет тип oword (128-разрядное число). Умножать мы будем по отдельности 32 бита каждого из числа. То есть у нас идет умножение 32 бита на 32 бита, поэтому результат
будет располагаться в регистрах EAX (младшие 32 бита результата) и EDX (старшие 32 бита). Для беззнакового умножения применяем инструкцию mul, для которой первый операнд всегда помещается
в EAX.
Вначале умножаем младшие 32 бита обоих чисел:
mov eax, dword ptr op1 mul dword ptr op2 mov dword ptr result, eax ; сохраняем младшие 32 бита результата mov ecx, edx
Младшие 32 бита, которые помещаются в EAX, сохраняем в младшие 32 бита переменной result. Старшие 32 бита - в регистр ECX.
Далее умножаем младшие 32 бита op1 на старшие 32 бита op2:
mov eax, dword ptr op1 mul dword ptr op2[4] ; получаем старшие 32 бита числа op2 add eax, ecx ; добавляем промежуточный результат умножения из ECX adc edx, 0 ; сложение с битом переноса mov ebx, eax ; сохраняем промежуточный результат mov ecx, edx
Запись
op2[4]означает, что получаем данные начиная с 5 байта числа op1.После умножения младшие 32 бита, которые помещаются в EAX, складываем со старшими 32 битами предыдущего умножения, которые были помещены в регистр ECX. В процессе сложения может возникнуть перенос, и будет установлен флаг переноса. Поэтому бит переноса прибавляем к старшим 32 битам текущего умножения из регистра EDX.
Далее умножаем старшие 32 бита op1 на младшие 32 бита op2:
mov eax, dword ptr op1[4] ; получаем старшие 32 бита числа op1 mul dword ptr op2 ; умножаем на младшие 32 бита op2 add eax, ebx ; добавляем промежуточный результат умножения из EBX mov dword ptr result[4], eax ; сохраняем частичный результат adc ecx, edx ; сложение с битом переноса
В данном случае мы опять же получаем данные для вторых 32 битов числа result. После умножения младшие 32 бита, которые помещаются в EAX, складываем с младшими 32 битами предыдущего умножения (так как это данные одного порядка) и помещаем результат во вторые 32 бита переменной result. .В процессе сложения может возникнуть перенос, и будет установлен флаг переноса. Поэтому опять же бит переноса прибавляем к старшим 32 битам текущего умножения из регистра EDX и складываем эти данные со старшими битами из предыдущего результата умножения.
На последнем этапе умножаем старшие 32 бита двух чисел.
mov eax, dword ptr op1[4] mul dword ptr op2[4] add eax, ecx ; добавляем промежуточный результат из ECX adc edx, 0 ; сложение с битом переноса mov dword ptr result[8], eax ; сохраняем младшую часть результата mov dword ptr result[12], edx ; сохраняем старшую часть результата
Младшие биты результата текущего умножения складываем с суммой старших 32 битов предыдущих двух результатов. И сохраняем эти данные в третьи 32 бита числа result. Страшие 32 бита складываем с битом переноса и сохраняем в старшие 32 бита числа result.
И в данном случае мы получим следующие вычисления:
ffffffffffffffffh * 10h (16 в десятичной - аналогично сдвигу влево на 4 разряда) = ffffffffffffffff0h или 00000000 0000000f ffffffff fffffff0
Используя данный алгоритм, можно умножать числа и большей разрядности.
- Глава 1. Введение в ассемблер Intel x86-64
- Глава 2. Основы ассемблера MASM для Intel x86-64
- Определение данных и их типы. Секция .data
- Инструкция mov. Копирование данных
- Сложение и вычитание. add и sub
- Переходы. Инструкция jmp
- Флаги состояния и условные переходы
- Сравнение. Инструкция CMP
- Инструкции условного копирования
- Логические операции
- Сдвиг и вращение
- Умножение. mul и imul
- Деление. Инструкции div и idiv
- Установка битов по условию. setc
- Манипуляции битами. BMI
- Константы
- Глава 3. Работа с данными и памятью
- Глава 4. Базовые конструкции
- Глава 5. Арифметика больших чисел
- Глава 6. Процедуры
- Глава 7. Организация программы
- Глава 8. FPU, SSE числа с плавающей точкой
- Регистры FPU
- Числа с плавающей точкой
- Загрузка данных и преобразование чисел в FPU
- Сложение чисел с плавающей точкой в FPU
- Вычитание чисел с плавающей точкой в FPU
- Умножение чисел с плавающей точкой в FPU
- Деление чисел с плавающей точкой в FPU
- Дополнительные математические инструкции FPU
- Сравнение чисел с плавающей точкой в FPU
- Расширения SSE для чисел с плавающей точкой
- Арифметика чисел с плавающей точкой в SSE
- Сравнение чисел с плавающей точкой в SSE
- Десятичная арифметика и двоично-десятичный формат BCD
- Глава 9. SIMD
- Расширения SSE и AVX/AVX2
- Копирование данных с помощью инструкций SIMD
- Копирование чисел с плавающей точкой
- Переупорядочивание данных
- Логические операции SSE/AVX
- Операции сдвига SSE/AVX
- Сложение с помощью инструкций SSE/AVX
- Вычитание с помощью инструкций SSE/AVX
- Умножение с помощью инструкций SSE/AVX
- Математические инструкции SSE/AVX
- Сравнение целых чисел в SSE/AVX
- Преобразования целых чисел в SSE/AVX
- Арифметические операции с плавающей точкой в SSE/AVX
- Сравнение чисел с плавающей точкой в SIMD
- Преобразование чисел с плавающей точкой в целые числа и обратно
- Загрузка в регистры константных значений
- Сохранение состояния регистров SSE/AVX
- Глава 10. Строки
- Глава 11. Макросы
- Глава 12. Взаимодействие с кодом на C/C++
- Глава 13. Взаимодействие с WinAPI
- Глава 14. Исследование и дизассемблирование файлов