Сопроцессор Neon и параллельные вычисления
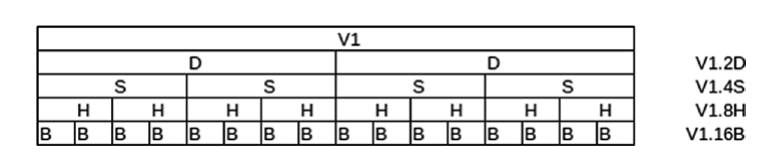
Сопроцессор Neon позволяет выполняеть одновременно несколько операций. Сопроцессор Neon работает с теми же регистрами, что и FPU, но позволяет также полностью задействовать 32 128-разрядных регистра, которые называются V0, V1, V2, ... V31

Стоит отметить, что сопроцессор NEON может помещать в эти регистры также и 128-разрядные целые числа, в этом случае регистры именуются Q0, ... Q31.
Но также сопроцессор Neon может обращаться к младшим 64 бит регистров Vn - 64-разрядным регистрам D0-D31.
Neon может работать как с числами с плавающей точкой, так и с целыми числами.
Сопроцессор Neon применяет концепцию дорожек/аллей (lane) для всех своих операций. Когда выбирается тип данных, процессор рассматривает регистр как разделенный учитывает на некоторое количество дорожек — одна дорожка для каждого объекта данных. Например, если мы работаем с 32-разрядными целыми числами и используем 128-разрядный регистр V, то регистр считается разделенным на четыре дорожки, по одной для каждого целого 32-разрядного числа. То есть мы можем поместить в 128-разрядный регистр 4 32-разрядных числа, и над каждым из этих чисел операции будут идти параллельно.
Арифметические операции
Сопроцессор Neon применяет все те же арифметические операции, которые доступны в ARM64 для целых чисел и чисел с плавающей точкой. Например, возьмем операцию сложения, которая имеет две формы: одна для сложения целых чисел (ADD) и одна для сложения чисел с плавающей точкой (FADD
ADD Vd.T, Vn.T, Vm.T // для сложения целых чисел FADD Vd.T, Vn.T, Vm.T // для сложения чисел с плавающей точкой
T представляет спецификатор, через который передается тип и размер используемых данных. Данный спецификатор может иметь следующие значения
Для операций с целыми числами (например, для инструкции ADD) может принимать значения 8B, 16B, 4H, 8H, 2S, 4S и 2D
Для операций с числами с плавающей точкой (например, для инструкции FADD) может принимать значения 4H, 8H, 2S, 4S и 2D
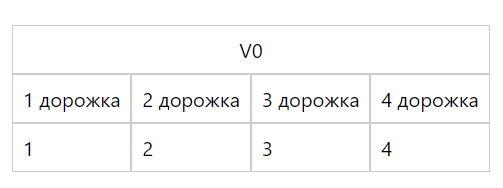
Рассмотрим небольшой пример. Допустим, нам надо возвести в квадрат четыре числа, пусть это будут числа .single. Для этого определим следующую программу:
.global main
main:
STR LR, [SP, #-16]!
LDR X20, =numbers // загружаем указатель на числа
LDR Q0, [X20] // загружаем 4 числа из numbers
FMUL V0.4S, V0.4S, V0.4S // V0 = V0 * V0
STR Q0, [X20] // сохраняем 4 числа обратно из регистра V0 в numbers
// выводим в цикле полученные числа
MOV W19, #4 // 4 числа
loop:
LDR S2, [X20] // указатель на первое число
FCVT D0, S2 // преобразуем single в double
FMOV X1, D0 // помещаем в X1 для вывода на консоль
LDR X0, =printNum // строка форматирования для вывода на консоль
BL printf // выводим на консоль расстояние
ADD X20, X20, #4 // переходим к следующему 4-байтному числу
SUBS W19, W19, #1 // уменьшаем счетчик цикла
B.NE loop // повторяем цикл, если еще есть числа
MOV X0, #0 // код возврата
LDR LR, [SP], #16
RET
.data
numbers: .single 1, 2, 3, 4
printNum: .asciz "%0.2f\n"
Итак, в секции .data под меткой numbers определены четыре числа single.
В программе сначала загружаем адрес метки numbers в регистр X20, а затем все числа в регистр Q0(он же регистр V0).
LDR X20, =numbers // загружаем указатель на числа LDR Q0, [X20] // загружаем 4 числа из numbers
Числа загружаются в регистры по порядку, то есть в S0 будет первое число 1, в S1 - второе число 2 и так далее.
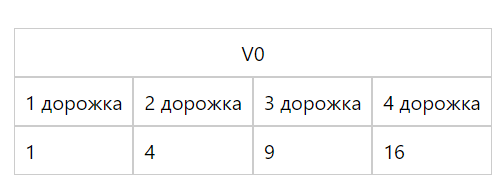
Далее выполняем возведение в квадрат, то есть умножаем каждое число на себя:
FMUL V0.4S, V0.4S, V0.4S // V0 = V0 * V0
Выражение V0.4S указывает на 4 значения типа single в регистре V0, то есть берем каждое число single и умножаем его на себя. Причем все четыре
числа будут умножаться друг на друга одновременно. Таким образом, для умножения 4-х 32-разрядных чисел друг на друга нам потребуется всего одна инструкция.
Ситуация после умножения
Далее сохраняем полученные числа обратно из V0 по адресу в X0, то есть в numbers.
STR Q0, [X20]
Затем в цикле выводим каждое из четырех числе на консоль с помощью функции printf языка C (Соответственно для компиляции применяется компилятор gcc). В итоге после компиляции программы и ее запуска на консоль будут выведены квадраты числе
1.00 4.00 9.00 16.00
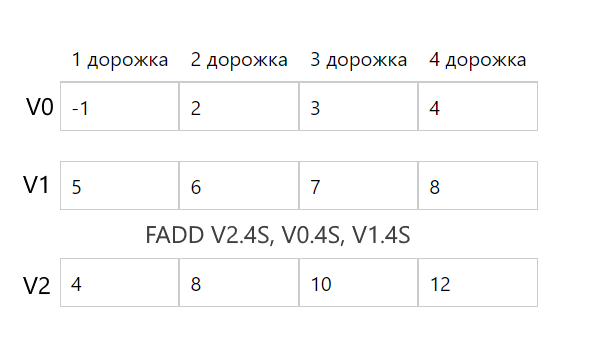
Другой пример - сложение чисел. Определим следующую программу:
.global main
main:
STR LR, [SP, #-16]!
LDR X20, =numbers1 // загружаем указатель на числа numbers1
LDP Q0, Q1, [X20], #(8*4) // в V0 загружаем numbers1, а в V1 - numbers2 и переходим к адресу numbers3
LDR Q2, [X20] // в V2 загружаем 4 числа из numbers3
FADD V2.4S, V0.4S, V1.4S // V2 = V0 + V1
STR Q2, [X20] // сохраняем 4 числа обратно из регистра V2 в numbers3
// выводим в цикле полученные числа
MOV W19, #4 // 4 числа
loop:
LDR S2, [X20] // указатель на первое число
FCVT D0, S2 // преобразуем single в double
FMOV X1, D0 // помещаем в X1 для вывода на консоль
LDR X0, =printNum // строка форматирования для вывода на консоль
BL printf // выводим на консоль расстояние
ADD X20, X20, #4 // переходим к следующему 4-байтному числу
SUBS W19, W19, #1 // уменьшаем счетчик цикла
B.NE loop // повторяем цикл, если еще есть числа
MOV X0, #0 // код возврата
LDR LR, [SP], #16
RET
.data
numbers1: .single -1, 2, 3, 4
numbers2: .single 5, 6, 7, 8
numbers3: .single 0, 0, 0, 0
printNum: .asciz "%0.2f\n"
Здесь мы собираемся сложить по парно числа numbers1 с числами numbers2 и результат сохранить в numbers3.
В программе загружаем в регистр X20 адрес метки numbers1 и затем загружаем numbers1 в V0, а numbers2 в V1:
LDR X20, =numbers1 // загружаем указатель на числа numbers1 LDP Q0, Q1, [X20], #(8*4) // в V0 загружаем numbers1, а в V1 - numbers2 и переходим к адресу numbers3
При этом увеличиваем адрес в X20 на 8 * 4 = 32 байта, то есть после этого X20 указывает на адрес метки numbers3. И загружаем эти числа в регистр V2
LDR Q2, [X20] // в V2 загружаем 4 числа из numbers3
Затем складываем числа в соответствующих дорожках в V0 и V1 и результат помещаем в регистр V2. В итоге опять регистры V0, V1, V2 будут разбиты на 4 дорожки, и вычисление суммы чисел из соответствующих дорожек будет производиться параллельно.
Консольный вывод программы:
4.00 8.00 10.00 12.00
Аналогичным образом мы можем работать и с другими типами данных, например, с целыми числами типа word, то есть 32-разрядными числами:
.global main
main:
STR LR, [SP, #-16]!
LDR X20, =numbers1 // загружаем указатель на числа numbers1
LDP Q0, Q1, [X20], #(8*4) // в V0 загружаем numbers1, а в V1 - numbers2 и переходим к адресу numbers3
LDR Q2, [X20] // в V2 загружаем 4 числа из numbers3
ADD V2.4S, V0.4S, V1.4S // V2 = V0 + V1
STR Q2, [X20] // сохраняем 4 числа обратно из регистра V2 в numbers3
// выводим в цикле полученные числа
MOV W19, #4 // 4 числа
loop:
LDR W1, [X20] // помещаем в X1 для вывода на консоль
LDR X0, =printNum // строка форматирования для вывода на консоль
BL printf // выводим на консоль расстояние
ADD X20, X20, #4 // переходим к следующему 4-байтному числу
SUBS W19, W19, #1 // уменьшаем счетчик цикла
B.NE loop // повторяем цикл, если еще есть числа
MOV X0, #0 // код возврата
LDR LR, [SP], #16
RET
.data
numbers1: .word 1, 2, 3, 4
numbers2: .word 5, 6, 7, 8
numbers3: .word 0, 0, 0, 0
printNum: .asciz "%d\n"
Доступ к дорожкам
Для доступа к значению в определенной дорожке применяются квадратные скобки, в которых указывается номер дорожки:
[номер_дорожки]
Отсчет дорожек начинается с нуля. Например:
MUL V2.4S, V1.4S, V0.4S[0]
Здесь числа во всех 4 дорожках регистра V1 умножаются на число в первой дорожке регистра V0, и результат - полученные 4 числа после умножения помещаются в 4 дорожки регистра V2.
- Глава 1. Введение в ассемблер ARM64
- Глава 2. Основы ассемблера ARM64
- Регистры процессора
- Инструкции. Реверс-инжиниринг программы
- Проверка значения регистра
- Инструкция MOV и копирование значений
- Операции сдвига
- Загрузка констант в регистры
- Копирование разрядов
- Расширение регистров знаком и нулем
- Сложение. Инструкция ADD
- Вычитание. Инструкция SUB
- Логические операторы
- Умножение. Инструкция MUL
- Деление. Инструкции SDIV и UDIV
- Инструкции аккумулятора MADD и MSUB
- Глава 3. Работа с данными и памятью
- Типы данных
- Символы
- Инструкция LDR. Загрузка данных
- Выравнивание данных
- Инструкция STR. Сохранение данных
- Арифметика адресов
- Директива .EQU. Определение констант
- Получение адреса
- Типы адресации. Адресация со смещением
- Преиндексная и постиндексная адресация
- Адресация относительно регистра PC
- STRB и манипуляции с символами в строке
- Загрузка и сохранение двух регистров. LDP и STP
- Стек
- Глава 4. Управление состоянием и переходы
- Флаги состояния
- Сложение и установка флагов. Инструкция ADDS
- Вычитание с установкой флагов. Инструкция SUBS
- Сложение со знаком переноса. ADC
- Вычитание с учетом флага переноса и SBC
- Безусловный и условный переходы
- Сравнение и инструкции CMP, CMN и TST
- Инструкции условного выбора
- Инструкция CCMP. Объединение условий
- Сравнение с переходом. Инструкции CBZ, CBNZ, TBZ и TBNZ
- Ветвление программы и условные конструкции
- Проверка сложных условий
- Имитация конструкции switch..case
- Циклы
- Практика. Программа перевода строки в верхний регистр
- Практика. Печать регистра на консоль
- Глава 5. Функции
- Глава 6. Системные вызовы Linux
- Глава 7. Взаимодействие с кодом C
- Глава 8. FPU, числа с плавающей точкой и сопроцессор Neon
- Глава 9. Разные примеры
- Глава 10. Формат ELF-файла
- Глава 11. Создание программ для MacOS ARM64
- Глава 12. Создание программ для Windows ARM64