Умножение матриц с помощью сопроцессора Neon
Умножение матриц является довольно распространенной задачей, которая применяется в самых различных вычислениях. И использование сопроцессора Neon позволяет оптимизировать умножение матриц. Так, матрица размером 3x3 фактически представляет три операции умножения матрицы на вектор:
Ccol1 = A ∗ Bcol1 Ccol2 = A ∗ Bcol2 Ccol3 = A ∗ Bcol3
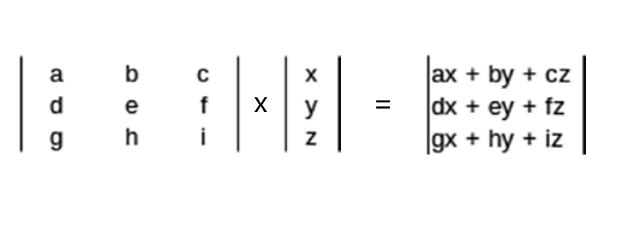
Если поместить числа a, d и g в отдельные дорожки регистра V сопроцессора Neon, а числа b, e и h в соответствующие дорожки второго регистра, а числа c, f и i в соответствующие дорожки третьего регистра, то можно вычислить столбец результирующей матрицы
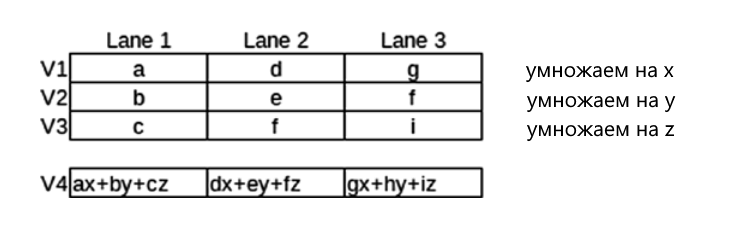
Итак, определим в файле main.s следующую программу
// Программа для умножения 2 матриц 3x3 с помощью сопроцессора NEON
//
// Используемые регистры:
// D0 - первый столбец матрицы A
// D1 - второй столбец матрицы A
// D2 - третий столбец матрицы A
// D3 - первый столбец матрицы B
// D4 - второй столбец матрицы B
// D5 - третий столбец матрицы B
// D6 - первый столбец матрицы C
// D7 - второй столбец матрицы C
// D8 - третий столбец матрицы C
.global main
main:
STP X19, X20, [SP, #-16]!
STR LR, [SP, #-16]!
// загружаем матрицу A в регистры D0, D1, D2
LDR X0, =A // адрес матрицы A
LDP D0, D1, [X0], #16
LDR D2, [X0]
// загружаем матрицу B в регистры D3, D4, D5
LDR X0, =B // адрес матрицы B
LDP D3, D4, [X0], #16
LDR D5, [X0]
// макрос для умножения матриц
.macro mulcol ccol bcol
MUL \ccol\().4H, V0.4H, \bcol\().4H[0]
MLA \ccol\().4H, V1.4H, \bcol\().4H[1]
MLA \ccol\().4H, V2.4H, \bcol\().4H[2]
.endm
mulcol V6, V3 // обрабатываем первый столбец
mulcol V7, V4 // обрабатываем второй столбец
mulcol V8, V5 // обрабатываем третий столбец
LDR X1, =C // адрес матрицы C
STP D6, D7, [X1], #16 // сохраняем данные в матрицу С
STR D8, [X1]
// выводим матрицу C на консоль
// проходим по 3 строкам и печатаем за раз числа из трех стоблцов
MOV W19, #3 // счетчик 3 строк
LDR X20, =C // адрес результирующей матрицы
printloop:
LDR X0, =prtstr // загружаем строку форматирования
// для вывода транспонируем матрицы, перейдя к стандартному расположению по столбцам
// прибавляем к адресу 2 для перехода к первому элементу следующей строки
// к адресу во второй инструкции ldrh добавляем 6, то есть 2+6=8=размер строки
// аналогично в третьей инструкции ldh прибавляем к адресу 2+14=16 байт, что представляет размер 2-й строки
LDRH W1, [X20], #2 // первый элемент текущей строки
LDRH W2, [X20, #6] // второй элемент текущей строки
LDRH W3, [X20, #14] // третий элемент текущей строки
BL printf // вызываем функцию printf
SUBS W19, W19, #1 // уменьшаем счетчик строк
B.NE printloop // пока не напечатаем все строки
MOV X0, #0 // код возврата
LDR LR, [SP], #16
LDP X19, X20, [SP], #16
RET
.data
// первая матрица
A: .short 1, 4, 7, 0
.short 2, 5, 8, 0
.short 3, 6, 9, 0
// вторая матрица
B: .short 9, 6, 3, 0
.short 8, 5, 2, 0
.short 7, 4, 1, 0
//результирующая матрица
C: .fill 12, 2, 0
prtstr: .asciz "%3d %3d %3d\n"
Здесь обе матрицы - A и B хранятся в порядке расположения столбцов, а матрица C генерируется также в порядке расположения столбцов, что позволяет упростить вычисления, поскольку так проще загружать данные в регистры NEON. Однако вывода на консоль в цикле данные печатаются в порядке расположения строк.
Основная работа выполняется в макросе. Сначала выполняем скалярное произведение
MUL \ccol\().4H, V0.4H, \bcol\().4H[0]
Данная инструкция после макроподстановок превращается в
MUL V6.4H, V0.4H, V3.4H[0]
Набор символов \() представляет разделитель между именем параметра и последующими символами. Здесь \() после имени параметра макроса
позволяет отделить название параметра от ".4H", иначе имя параметра будет рассматриваться как "ccol.4H".
Таким образом, перемножаем каждую дорожку в регистре V0 на число из соответствующей дорожки из регистра V3. Для доступа к значению в определенной дорожке применяются квадратные скобки, в которых указывается номер дорожки:
[номер_дорожки]
Отсчет дорожек начинается с нуля.
Последующие две инструкции макроса выполняют умножени с прибавлением:
MLA \ccol\().4H, V1.4H, \bcol\().4H[1] MLA \ccol\().4H, V2.4H, \bcol\().4H[2]
После определения макроса вызываем его три раза - по одному разу для каждого столбца
mulcol V6, V3 // обрабатываем первый столбец mulcol V7, V4 // обрабатываем второй столбец mulcol V8, V5 // обрабатываем третий столбец
Скомпилируем программу с помощью компилятора gcc и запустим на выполнение. В итоге консоль должна вывести матрицу С построчно
30 24 18 84 69 54 138 114 90
- Глава 1. Введение в ассемблер ARM64
- Глава 2. Основы ассемблера ARM64
- Регистры процессора
- Инструкции. Реверс-инжиниринг программы
- Проверка значения регистра
- Инструкция MOV и копирование значений
- Операции сдвига
- Загрузка констант в регистры
- Копирование разрядов
- Расширение регистров знаком и нулем
- Сложение. Инструкция ADD
- Вычитание. Инструкция SUB
- Логические операторы
- Умножение. Инструкция MUL
- Деление. Инструкции SDIV и UDIV
- Инструкции аккумулятора MADD и MSUB
- Глава 3. Работа с данными и памятью
- Типы данных
- Символы
- Инструкция LDR. Загрузка данных
- Выравнивание данных
- Инструкция STR. Сохранение данных
- Арифметика адресов
- Директива .EQU. Определение констант
- Получение адреса
- Типы адресации. Адресация со смещением
- Преиндексная и постиндексная адресация
- Адресация относительно регистра PC
- STRB и манипуляции с символами в строке
- Загрузка и сохранение двух регистров. LDP и STP
- Стек
- Глава 4. Управление состоянием и переходы
- Флаги состояния
- Сложение и установка флагов. Инструкция ADDS
- Вычитание с установкой флагов. Инструкция SUBS
- Сложение со знаком переноса. ADC
- Вычитание с учетом флага переноса и SBC
- Безусловный и условный переходы
- Сравнение и инструкции CMP, CMN и TST
- Инструкции условного выбора
- Инструкция CCMP. Объединение условий
- Сравнение с переходом. Инструкции CBZ, CBNZ, TBZ и TBNZ
- Ветвление программы и условные конструкции
- Проверка сложных условий
- Имитация конструкции switch..case
- Циклы
- Практика. Программа перевода строки в верхний регистр
- Практика. Печать регистра на консоль
- Глава 5. Функции
- Глава 6. Системные вызовы Linux
- Глава 7. Взаимодействие с кодом C
- Глава 8. FPU, числа с плавающей точкой и сопроцессор Neon
- Глава 9. Разные примеры
- Глава 10. Формат ELF-файла
- Глава 11. Создание программ для MacOS ARM64
- Глава 12. Создание программ для Windows ARM64