Работа с данными и памятью
Типы данных
Перед загрузкой данных в/из памяти сначала надо определить память, с которой будет идти работа. Ассемблер GNU предоставляет ряд директив для выделения памяти для использования в программе.
.ascii: строка в двойных кавычках
.asciz: строка ascii, которая заканчивается 0-вым байтом
.byte: целое число размером в 1 байт
.short: целое число размером в 2 байта (так называемое полуслово - hlf-word)
.word: целое число размером в 4 байта (слово)
.quad: целое число размером в 8 байт (двойное слово)
.octa: целое число размером в 16 байт (четверное слово)
.float: число с плавающей точкой одинарной точности
.double: число с плавающей точкой двойной точности
Мы можем определить числа в одном из следующих форматов:
Число в десятичной системе, которое может содержать цифры от 0 до 9 и должно начинаться с любой цифры кроме 0
Число в восьмеричной системе, которое может содержать цифры от 0 до 7 и должно начинаться с нуля
Число в двоичной системе, которое может содержать цифры 0 и 1 и должно начинаться с символов 0b или 0B
Число в шестнадцатеричной системе, которое может содержать шестнадцатеричные цифры от 0 до F и должно начинаться с символов 0x или 0X
Число с плавающей точкой, которое начинается с символов 0f или 0e, за которым идет число с плавающей точкой
Для определения памяти в программе предназначена секция .data. Например:
.global _start
_start:
// выход из программы
MOV X0, 0 // код возврата - 0
MOV X8, #93 // устанавливаем функцию Linux для выхода из программы
SVC 0 // Вызываем функцию Linux
.data
mybyte: .byte 1 // определяем один байт, который равен 1
myword: .word 18 // определяем одно слово (4 байта), которое равно 18
myshort: .short 3 // определяем двухбайтное число, которое равно 3
myquad: .quad 1248 // определяем двойное слово (8 байт), которое равно 1248
myocta: .octa 12 // определяем четверное слово (16 байт), которое равно 12
hello: .ascii "Hello\n" // определяем строку
message: .asciz "Hi Wordl" // определяем строку, которая заканчивается нулевым байтом
В данном случае для каждого отдельного кусочка данных определена метка. Например, на метку mybyte проецируется байт, который имеет значение 15.
Определенные в секции .data еще можно назвать глобальными переменными, поскольку они доступны глобально -
в любом месте прогаммы, а инструкции могут динамически изменять их значения.
Перед целыми числами можно использовать два знака:
- (отрицательное значение) определяет дополнение числа до двух
~ определяет дополнение числа до единицы
Например
byte1: .byte -0x45 byte1: .byte -33, byte1: .byte ~0b00111001
Расположение данных
Стоит учитывать, что данные, определенные в секции .data, в памяти располагаются сплошняком. Например, возьмем следующее определение данных:
.data
n1: .word 12 // 4 байта
n2: .short 13 // 2 байта
n3: .byte 14 // 1 байт
n4: .byte 15 // 1 байт
В памяти для секции .data выделяется некоторая область, где вначале располагается число n1, которое занимает 4 байта. Сразу ним располагается число n2, которое занимает 2 байта, и
далее идут числа n3 и n4, которые занимают по 1 байту. Допустим, секция .data располагается в памяти по адресу 0xff00, тогда расположение данных
упрощенно могло выглядеть следующим образом:
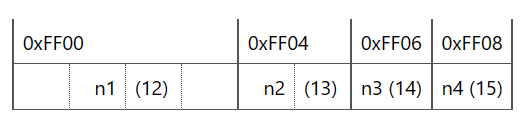
Это важное обстоятельство, поскольку позволяет нам, используя адрес одной переменной в памяти, обращаться к другим данным, которые располагаются до или после переменной.
Массив данных
Можно определять сразу набор или массив значений через запятую:
.data
bytes: .byte 74, 0112, 0b00101010, 0x4A, 0X4a
Здесь определяется 5 байт, каждый из которых имеет одно и то же значение. Мы можем определить значения в десятичной, восьмеричной, двоичной, шестнадцатеричной системах. При этом значения могут представлять результат выражений, которые вычисляет ассемблер, когда компилирует программу.
Определение наборов данных
Для упрошения определения наборов большего размера можно использовать инструкцию .fill, которая имеет следующую форму:
.fill repeat, size, value
Эта инструкция повторяет значение (value) определенного размера (size) определенное количество раз (repeat):
.data
zeros: .fill 10, 4, 0
Эта инструкция создает блок памяти из 10-ти 4-байтовых чисел (слов - тип .word), каждое из которых равно нулю.
Еще одна конструкция - .rept:
.rept count ... .endr
Повторяет выражения между .rept и .endr столько раз, сколько указано в параметре count. Например:
rpn: .rept 3
.byte 0, 1, 2
.endr
Здесь создается 3 раза по 3 байта - 0, 1, 2. То есть этот код будет эквивалентен следующему:
.byte 0, 1, 2 .byte 0, 1, 2 .byte 0, 1, 2
- Глава 1. Введение в ассемблер ARM64
- Глава 2. Основы ассемблера ARM64
- Регистры процессора
- Инструкции. Реверс-инжиниринг программы
- Проверка значения регистра
- Инструкция MOV и копирование значений
- Операции сдвига
- Загрузка констант в регистры
- Копирование разрядов
- Расширение регистров знаком и нулем
- Сложение. Инструкция ADD
- Вычитание. Инструкция SUB
- Логические операторы
- Умножение. Инструкция MUL
- Деление. Инструкции SDIV и UDIV
- Инструкции аккумулятора MADD и MSUB
- Глава 3. Работа с данными и памятью
- Типы данных
- Символы
- Инструкция LDR. Загрузка данных
- Выравнивание данных
- Инструкция STR. Сохранение данных
- Арифметика адресов
- Директива .EQU. Определение констант
- Получение адреса
- Типы адресации. Адресация со смещением
- Преиндексная и постиндексная адресация
- Адресация относительно регистра PC
- STRB и манипуляции с символами в строке
- Загрузка и сохранение двух регистров. LDP и STP
- Стек
- Глава 4. Управление состоянием и переходы
- Флаги состояния
- Сложение и установка флагов. Инструкция ADDS
- Вычитание с установкой флагов. Инструкция SUBS
- Сложение со знаком переноса. ADC
- Вычитание с учетом флага переноса и SBC
- Безусловный и условный переходы
- Сравнение и инструкции CMP, CMN и TST
- Инструкции условного выбора
- Инструкция CCMP. Объединение условий
- Сравнение с переходом. Инструкции CBZ, CBNZ, TBZ и TBNZ
- Ветвление программы и условные конструкции
- Проверка сложных условий
- Имитация конструкции switch..case
- Циклы
- Практика. Программа перевода строки в верхний регистр
- Практика. Печать регистра на консоль
- Глава 5. Функции
- Глава 6. Системные вызовы Linux
- Глава 7. Взаимодействие с кодом C
- Глава 8. FPU, числа с плавающей точкой и сопроцессор Neon
- Глава 9. Разные примеры
- Глава 10. Формат ELF-файла
- Глава 11. Создание программ для MacOS ARM64
- Глава 12. Создание программ для Windows ARM64