UNION
Оператор UNION подобно inner join или outer join позволяет соединить две таблицы. Но в отличие от inner/outer join объединения соединяют не столбцы разных таблиц, а два однотипных набора в один. Формальный синтаксис объединения:
SELECT_выражение1 UNION [ALL] SELECT_выражение2 [UNION [ALL] SELECT_выражениеN]
Например, пусть в базе данных будут две отдельные таблицы для клиентов банка (таблица Customers) и для сотрудников банка (таблица Employees):
USE usersdb;
CREATE TABLE Customers
(
Id INT IDENTITY PRIMARY KEY,
FirstName NVARCHAR(20) NOT NULL,
LastName NVARCHAR(20) NOT NULL,
AccountSum MONEY
);
CREATE TABLE Employees
(
Id INT IDENTITY PRIMARY KEY,
FirstName NVARCHAR(20) NOT NULL,
LastName NVARCHAR(20) NOT NULL,
);
INSERT INTO Customers VALUES
('Tom', 'Smith', 2000),
('Sam', 'Brown', 3000),
('Mark', 'Adams', 2500),
('Paul', 'Ins', 4200),
('John', 'Smith', 2800),
('Tim', 'Cook', 2800)
INSERT INTO Employees VALUES
('Homer', 'Simpson'),
('Tom', 'Smith'),
('Mark', 'Adams'),
('Nick', 'Svensson')
Здесь мы можем заметить, что обе таблицы, несмотря на наличие различных данных, могут характеризоваться двумя общими атрибутами - именем (FirstName) и фамилией (LastName). Выберем сразу всех клиентов банка и его сотрудников из обеих таблиц:
SELECT FirstName, LastName FROM Customers UNION SELECT FirstName, LastName FROM Employees
В данном случае из первой таблицы выбираются два значения - имя и фамилия клиента. Из второй таблицы Employees также выбираются два значения - имя и фамилия сотрудников. То есть при объединении количество выбираемых столбцов и их тип совпадают для обеих выборок.
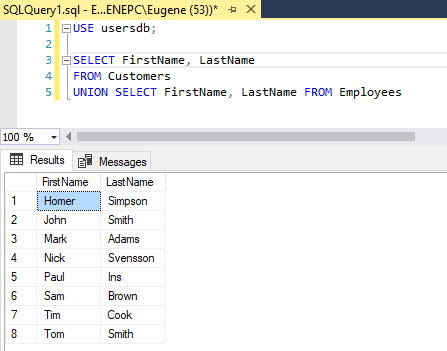
При этом названия столбцов объединенной выборки будут совпадать с названия столбцов первой выборки. И если мы захотим при этом еще произвести сортировку, то в выражениях ORDER BY необходимо ориентироваться именно на названия столбцов первой выборки:
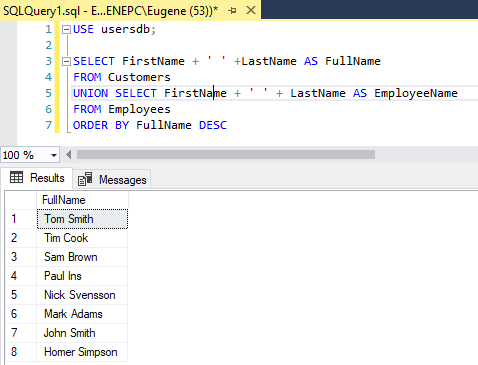
SELECT FirstName + ' ' +LastName AS FullName FROM Customers UNION SELECT FirstName + ' ' + LastName AS EmployeeName FROM Employees ORDER BY FullName DESC
В данном случае каждая выборка имеет по одному столбцу, который представляет объединение имени и фамилии клиента или сотрудника. Но в случае с клиентами столбец будет называться FullName, а в случае с сотрудниками - EmployeeName. Тем не менее для сортировки применяется название столбца из первой выборки и он же будет в результирующей выборке:
Если же в одной выборке больше столбцов, чем в другой, то они не смогут быть объединены. Например, в следующем случае объединение завершится с ошибкой:
SELECT FirstName, LastName, AccountSum FROM Customers UNION SELECT FirstName, LastName FROM Employees
Также соответствующие столбцы должны соответствовать по типу. Так, следующий пример завершится с ошибкой из-за не соответствия по типу данных:
SELECT FirstName, LastName FROM Customers UNION SELECT Id, LastName FROM Employees
В данном случае первый столбец первой выборки имеет тип NVARCHAR, то есть хранит строку. Первый столбец второй выборки - Id имеет тип INT, то есть хранит число.
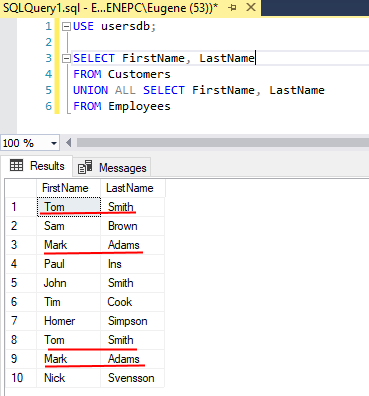
Если оба объединяемых набора содержат в строках идентичные значения, то при объединении повторяющиеся строки удаляются. Например, в случае с таблицами Customers и Employees сотрудники банка могут быть одновременно его клиентами и содержаться в обеих таблицах. При объединении в примерах выше всех дублирующиеся строки удалялись. Если же необходимо при объединении сохранить все, в том числе повторяющиеся строки, то для этого необходимо использовать оператор ALL:
SELECT FirstName, LastName FROM Customers UNION ALL SELECT FirstName, LastName FROM Employees
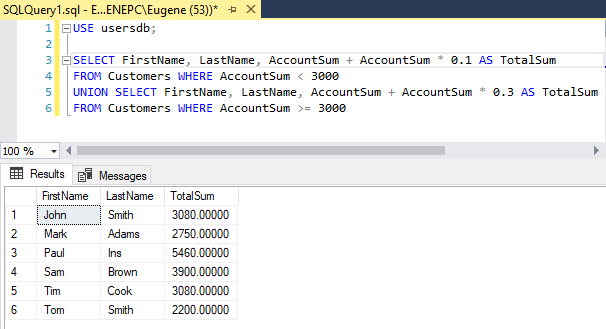
Объединять выборки можно и из одной и той же таблицы. Например, в зависимости от суммы на счете клиента нам надо начислять ему определенные проценты:
SELECT FirstName, LastName, AccountSum + AccountSum * 0.1 AS TotalSum FROM Customers WHERE AccountSum < 3000 UNION SELECT FirstName, LastName, AccountSum + AccountSum * 0.3 AS TotalSum FROM Customers WHERE AccountSum >= 3000
В данном случае если сумма меньше 3000, то начисляются проценты в размере 10% от суммы на счете. Если на счете больше 3000, то проценты увеличиваются до 30%.
- Глава 1. Введение в MS SQL Server и T-SQL
- Глава 2. Начало работы с MS SQL Server
- Глава 3. Основы T-SQL. DDL
- Глава 4. Основы T-SQL. DML
- Глава 5. Группировка
- Глава 6. Подзапросы
- Глава 7. Соединение таблиц
- Глава 8. Встроенные функции
- Глава 9. Переменные и управляющие конструкции
- Глава 10. Представления и табличные объекты
- Глава 11. Хранимые процедуры
- Глава 12. Триггеры