Работа с данными и памятью
Определение переменных и типы данных. Секция .data
Типы данных
Все используемые в программе данные имеют определенный тип, который определяется разрядностью данных. Архитектура Intel x86-64 поддерживает следующие типы данных:
byte: 8-разрядное целое число
word: 16-разрядное целое число или слово
dword: 32-разрядное целое число или двойное слово
qword: 64-разрядное целое число или четверное слово
Например, 8-разрядный регистр AL по сути представляет байт, 16-разрядный AX - слово, 32-разрядный EAX - двойное слово, а 64-разрядный регистр RAX - четверное слово.
Определение данных в программе
Ассемблер NASM позволяет определять в программе объекты, которые хранят некоторые данные, и на протяжении программы мы можем использовать эти данные, изменять их. Подобные данные еще называются переменными. Объявления данных имеют следующую форму:
label directive value
label или метка представляет название переменной, которая может представлять произвольный идентифкатор. После названия переменной идет directive -
директива, которая устанавливает тип данных. Это может быть одна из следующих директив:
db (define byte): определяет целое число размером в 1 байт
dw (define word): определяет целое число размером в 2 байта (слово)
dd (define dword): определяет целое число размером в 4 байта (так называемое двойное слово)
dq (define qword/quad): определяет целое число размером в 8 байт (четверное слово)
После директивы данных идет собственно значение. Например:
number dq 22
Стоит отметить, что после названия переменной можно указывать двоеточие, как для обычной метки, но оно в принципе необязательно:
number: dq 22
Здесь определена переменная number, которая имеет тип qword, то есть представляет 8 байт, и которая равна 22.
С каждой переменной ассемблер будет ассоциировать некоторый свободный участок памяти. Например, переменная number имеет тип qword и занимает 8 байт,
соответственно ассемблер найдет в памяти свободный 8 байт и ассоциирует их с этой переменной.
Расположение и использование данных
Где определяются данные? В программе на ассемблере можно опредлять данные в различных секциях.
Определение данных в секции .text
Например, в секции кода .text:
global _start
section .text
number: dq 123 ; определяем объект number внутри секции .text
_start:
; остальной код программы
Единственное, что не следует смешивать определение данных с инструкциями, поэтому при определении данных в секции .text данные должны определяться либо до первой инструкции, либо после последней инструкции.
После определения переменные можно использовать в программе как обычные данные. Например, можно помещать в регистр или, наоборот, сохранять значение из регистра в переменную. Как же получить переменную, например, в регистр?
Стоит сразу сказать, что имя переменной, например, "number", само по себе представляет ее адрес, а не непосредственное значение. Например, возьмем следующую программу на Linux:
global _start
section .text
number: dq 124 ; определяем объект number внутри секции .text
_start:
mov rdi, number
mov rax, 60
syscall
Здесь в регистр RDI помещается адрес переменной number, но не само значение. Чтобы получить значение, надо поместить название переменной в квадратные скобки:
[название_переменной]Например, возьмем следующую программу на Linux:
global _start
section .text
number: dq 124 ; определяем объект number внутри секции .text
_start:
mov rdi, [number] ; rdi = 124
mov rax, 60
syscall
Инструкция mov rdi, [number] помещает в регистр rdi значение переменной number, то есть число 124.
Выше мы рассмотрели программу получения значения переменной на Linux. На Windows все немного сложнее, многое зависит от компоновщика, который применяется при сборке программы в исполняемое приложение. Например, возьмем следующую программу на Windows:
global _start
section .text
number: db 124 ; определяем объект number внутри секции .text
_start:
mov rax, [number]
ret
При использовании компоновщика ld, который идет в комплекте GCC, мы столкнемся с ошибкой релокаций:
c:\asm>nasm -f win64 hello.asm -o hello.o c:\asm>ld hello.o -o hello.exe hello.o:hello.asm:(.text+0x5): relocation truncated to fit: IMAGE_REL_AMD64_ADDR32 against `.text' c:\asm>
Если мы используем компоновщик от Microsoft - link.exe, то мы также столкнемся с ошибкой релокаций, хотя само сообщение об ошибке будет выглядеть несколько иначе:
c:\asm>nasm -f win64 hello.asm -o hello.o c:\asm>link hello.o /entry:_start /subsystem:console /out:hello.exe Microsoft (R) Incremental Linker Version 14.37.32824.0 Copyright (C) Microsoft Corporation. All rights reserved. hello.o : error LNK2017: 'ADDR32' relocation to '.text' invalid without /LARGEADDRESSAWARE:NO LINK : fatal error LNK1165: link failed because of fixup errors c:\asm>
Суть ошибки: мы пытаемся создать 64-разрядное приложение, которое использует 32-разрядные адреса. В принципе ошибка подсказывает один из вариантов решений - добавить к вызову компоновщика дополнительную опцию - /LARGEADDRESSAWARE:NO:
link hello.o /entry:_start /subsystem:console /out:hello.exe /LARGEADDRESSAWARE:NO
Тем не менее это решает проблему отчасти. В качестве решения мы можем использовать оператор rel, который позволяет использовать адрес относительно регистра RIP (указателя инструкций):
[rel название_переменной]
Так, изменим программу для Windows:
global _start
section .text
number: dq 124 ; определяем объект number внутри секции .text
_start:
mov rax, [rel number] ; используем адрес number относительно регистра RIP
ret
Теперь при использовании компоновщика от Microsoft у нас не возникнет проблем:
c:\asm>nasm -f win64 hello.asm -o hello.o c:\asm>link hello.o /entry:_start /subsystem:console /out:hello2.exe Microsoft (R) Incremental Linker Version 14.37.32824.0 Copyright (C) Microsoft Corporation. All rights reserved. c:\asm>hello2.exe c:\asm>echo 124 124 c:\asm>
Тем не менее при использовании компоновщика ld от GCC мы хоть и скомпонуем программу, но получим некорреткные результаты:
c:\asm>nasm -f win64 hello.asm -o hello.o c:\asm>ld hello.o -o hello.exe c:\asm>hello.exe c:\asm>echo -1073741819 -1073741819 c:\asm>
Таким образом, в зависимости от используемого компоновщика мы можем получить разные результаты. Мы можем играть с параметрами компоновщиков, но в любом случае секция .text не слишком хорошо подходит для хранения данных.
Секция .data
Секция данных задается с помощью директивы .data. Эта директива сообщает ассемблеру, что дальше идут объявления данных. Например, программа на Linux:
global _start
section .data ; определение секции .data
number dq 125 ; определяем объект number внутри секции .data
section .text
_start:
mov rdi, [number] ; получаем данные из секции .data
mov rax, 60
syscall
Аналогичная программа для Windows:
global _start
section .data ; определение секции .data
number dq 125 ; определяем объект number внутри секции .data
section .text
_start:
mov rax, [rel number]
ret
Стоит отметить, что в отличие от программы для Linux, здесь применяется оператор rel. Тем не менее и компоновщик ld от GCC, и компоновщик от Microsoft успешно скомпонуют данную программу.
Если секция .data содержит несколько переменных, то ассемблер с каждой из этих переменной ассоциирует некоторый участок памяти. Причем
в памяти все переменные будут расположены друг за другом. Например, возьмем следующую секцию данных
section .data i64 dq 8 i32 dd 4 i16 dw 2 i8 db 1
Для переменной i8 выделяется 1 байт, для i16 - 2 байта, для i32 - 4 байта и для i64 - 8 байт. В итоге для секции .data будет выделен блок памяти, который занимает не менее 15 байт, где переменные будут располагаться следующим образом:
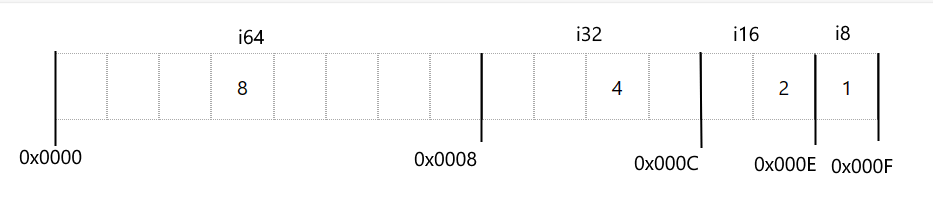
Допустим, для переменной i64 выделено 8 байт по адресу 0x0000, тогда i32 располагается по адресу 0x0008, а i16 - по адресу 0x000С и i8 по адресу 0x000E.
Изменение данных
Eще один момент, который надо учитывать при определении данных в секции .text: данные, определенные в этой секции, по сути являются константами, то есть их значения нельзя изменить (хотя для простоты все определенные таким образом данные в программе именуют переменными). Например, возьмем следующую программу под Linux:
global _start
section .text
number dq 124 ; определяем объект number внутри секции .text
_start:
mov rdx, 111
mov [number], rdx ; пытаемся записать в number число 111
mov rdi, [number]
mov rax, 60
syscall
Здесь мы пытаемся поместить значение регистра RDX в переменную number:
mov [number], rdx
Однако объект number определен в секции .text, поэтому он не изменяем. И хотя ассемблер может успешно скомпилировать программу, Linux сгенерирует общую ошибку защиты (general protection fault), если мы попытаемся сохранить какие-либо данные в секции кода:
eugene@Eugene:~/asm# nasm -f elf64 hello.asm -o hello.o eugene@Eugene:~/asm# ld hello.o -o hello eugene@Eugene:~/asm# ./hello Segmentation fault eugene@Eugene:~/asm#
Собственно при определении объектов в секции .text у нас получаются константы - объекты, значения которых нельзя изменить.
Поэтому для определения переменных и в целом для определения данных больше подходят другие секции, в частности, секция .data. Изменим программу, перенеся данные в секуцию .data:
global _start
section .data ; определение секции .data
number dq 125 ; определяем объект number внутри секции .data
section .text
_start:
mov rdx, 111
mov [number], rdx ; пытаемся записать в number число 111
mov rdi, [number]
mov rax, 60
syscall
Теперь при выполнении проблем не возникнет:
eugene@Eugene:~/asm# nasm -f elf64 hello.asm -o hello.o eugene@Eugene:~/asm# ld hello.o -o hello eugene@Eugene:~/asm# ./hello eugene@Eugene:~/asm# echo $? 111 eugene@Eugene:~/asm#
Аналогичный пример для Windows:
global _start
section .data ; определение секции .data
number dq 125 ; определяем объект number внутри секции .data
section .text
_start:
mov rdx, 111
mov [rel number], rdx ; пытаемся записать в number число 111
mov rax, [rel number]
ret
Определение массивов данных
Ассемблер NASM позволяет определить набор данных. Если нам известны все элементы набора, то мы их можем перечислить через запятую:
nums dq 11, 12, 13, 14, 15, 16, 17
Здесь переменная nums представляет набор из 7 чисел, каждое из которых занимает 8 байтов. При при обращении к этому набору по имени переменной мы фактически обращаемся к первому элементу этого набора:
global _start
section .data
nums dq 11, 12, 13, 14, 15, 16, 17 ; набор из 7-ми 8-разрядных чисел
section .text
_start:
mov rdi, [nums] ; rdi = 11
mov rax, 60
syscall
С помощью директивы times можно определить массив, в котором некоторое значение повторяется определенное количество раз:
times количество тип значение
Первый параметр директивы указывает на количество - сколько определить чисел. Второй параметр представляет тип чисел, например, db, dq и т.д. Третий параметр
указывает на само значение. Например:
numbers: times 10 db 2
Здесь переменная numbers представляет массив из 10 чисел, каждое из которых равно 2 и представляет 1 байт (тип db)
Для упрошения определения наборов большего размера NASM имеет дополнительные директивы resX. Вместо X указывается суффикс, обозначающий
тип данных:
resb: выделяет некоторое количество байт
resw: выделяет некоторое количество слов (2-х байтовых чисел)
resd: выделяет некоторое количество двойных слов (4-х байтовых чисел)
resq: выделяет некоторое количество четверных слов (8-х байтовых чисел)
В качестве параметра этим директивам передается количество чисел в создаваемом наборе. По умолчанию каждое такое число будет инициализировано нулем. Например:
buffer resb 10
Определяет переменную buffer - набор из 10 байт. Другой пример:
numbers resq 5
Определяет набор из 5 четверных слов.
Дополнительные секции данных
Кроме собственно секции .data в программе на ассемблере может использоваться еще ряд секций. Секция
.rodata содержит данные, которые нельзя изменить (то есть по сути константы).
Он загружается в память при загрузке приложения и помечается как доступный только для чтения. Попытки записи в эту память приведут к остановке программы.
global _start
section .rodata ; определение секции .rodata
number dq 125 ; число можно получить, но нельзя изменить
section .text
_start:
mov rdi, [number]
; mov [number], rdi ; при попытке записи - Segmentation fault
mov rax, 60
syscall
Секция .bss (сокращение от Block Started by Symbol) содержит неинициализированные данные, для которых известен размер, но неизвестно значение. Это экономит место в исполняемом файле,
особенно если здесь большой объем данных. Операционная система инициализирует раздел .bss всеми нулями. Можно зарезервировать данные в разделе .bss,
используя директивы resb/resw/resd/resq. Например, если нам нужен массив, значения которого в начале программы не столь важны и который инициализируется уже по ходу программу,
например, мы в него загружаем данные из файла, то подобный массив как раз можно определить в секции .bss:
global _start
section .bss
buffer resq 1024 ; массив из 1024-х 8-байтовых чисел
section .text
_start:
mov rdi, [buffer] ; rdi = 0
mov rax, 60
syscall
В данном случае в секции .bss определен массив из 1024-х 8-байтовых чисел, который в сумме занимает 1024 * 8 = 8184 байт. Однако поскольку этот массив размещен в секции
.bss, то эти байты не входят в размер файла, они будут выделяться при запуске программы.
Преобразования данных
При работе с данными в ассемблере мы вынуждены учитывать их разрядность. Например, возьмем следующий код программы для Linux:
global _start
section .data
number db 12 ; однобайтовое число
section .text
_start:
mov rdi, [number]
mov rax, 60
syscall
Здесь значение 8-разрядного числа number помещается в 64-разрядный регистр RDI. При компиляции и выполнении программ у нас не возникнет особых проблем:
eugene@Eugene:~/asm# nasm -f elf64 hello.asm -o hello.o eugene@Eugene:~/asm# ld hello.o -o hello eugene@Eugene:~/asm# ./hello eugene@Eugene:~/asm# echo $? 12 eugene@Eugene:~/asm#
Аналогично не возникнет проблем с программой для Windows:
global _start
section .data
number db 12 ; однобайтовое число
section .text
_start:
mov rax, [rel number]
ret
Консольный вывод:
c:\asm>nasm -f win64 hello.asm -o hello.o c:\asm>ld hello.o -o hello.exe c:\asm>hello.exe c:\asm>echo %ERRORLEVEL% 12 c:\asm>
Изменим программу для Windows следующим образом:
global _start
section .data
nums db 1, 2, 0, 0, 0, 0, 0, 0 ; 8 однобайтовых числа
section .text
_start:
mov rax, [rel nums]
ret
Тепепь nums представляет массив из 8 байтов. Имя переменной - адрес первого элемента массива, соответственно мы ожидаем получить в регистр RAX первый элемент массива - число 1. Однако статусный код возврата покажет что-то не то:
c:\asm>nasm -f win64 hello.asm -o hello.o c:\asm>ld hello.o -o hello.exe c:\asm>hello.exe c:\asm>echo %ERRORLEVEL% 513 c:\asm>
Я специально выбрал версию для Windows, потому что на Linux в принципе мы можем и не столкнуться с этой проблемой. Почему мы получаем число 513?
Число 513 в двоичной системе равно 1000000001 или добавим в начало ненужные нули и получим 00000010_00000001.
Младший байт этого числа 00000001 равен 1, а следующий байт 00000010 в десятичной системе равен 2. То есть 8 байтов массива были последовательно загружены в регистр
RAX. Что неудивительно, так как регистр RAX имеет размер 8 байт. Но, допустим, нам надо загрузить только первый один единственный байт. В этом случае нам надо применить преобразования. Преобразования
производятся с помощью операторов-названий типов данных:
byte: преобразует в байт
word: преобразует в слово
dword: преобразует в двойное слов
qword: преобразует в четверное слово
Так, строку
mov rax, [rel nums]
нам надо изменить на строку
movzx rax, byte [rel nums]
Выражение byte [rel nums] или byte [nums] получает из массива nums первый байт, а инструкция movzx помещает этот байт в регистр (в младший байт), заполняя остальные байты регистра нулями
Аналогично когда мы помещаем в переменную или по некоторому адресу в памяти непосредственное значение, то нам надо указать размер данных:
mov byte [nums], 101
Например, в программе для Linux поместим байт в массив:
global _start
section .data
nums db 12, 13, 14, 15 ; 4 однобайтовых числа число
section .text
_start:
mov byte [nums], 101 ; nums = 101, 13, 14, 15
movzx rdi, byte [nums] ; rdi = 101
mov rax, 60
syscall
- Глава 1. Введение в архитектуру Intel x86-64 и ассемблер NASM
- Глава 2. Основы ассемблера NASM
- Инструкция MOV. Копирование данных
- Сложение и вычитание
- Переходы. Инструкция jmp
- Флаги состояния и условные переходы
- Сравнение. Инструкция CMP
- Инструкции условного копирования
- Инструкция цикла loop и jrcxz
- Умножение. Инструкции mul и imul
- Деление. Инструкции div и idiv
- Логические операции
- Сдвиг и вращение
- Глава 3. Работа с данными и памятью
- Глава 4. Функции
- Глава 5. Системные вызовы
- Глава 6. Взаимодействие кода ассемблера и C/C++
- Глава 7. SIMD
- Числа с плавающей точкой
- Расширения SSE и AVX/AVX2
- Копирование данных с помощью инструкций SIMD
- Преобразование чисел с плавающей точкой в целые числа и обратно
- Арифметика чисел с плавающей точкой
- Сравнение чисел с плавающей точкой
- Операции сдвига SSE/AVX
- Логические операции над векторами
- Сложение с помощью инструкций SSE/AVX
- Вычитание с помощью инструкций SSE/AVX
- Умножение с помощью инструкций SSE/AVX
- Математические инструкции SSE/AVX
- Сравнение целых чисел в SSE/AVX
- Арифметические операции с векторами чисел с плавающей точкой
- Сохранение состояния регистров SSE/AVX
- Глава 8. Препроцессор
- Глава 9. Разделяемые библиотеки в Linux
- Глава 10. Дополнительные статьи